Developer Tools●●Solid
LLMWise – Compare, Blend, and Judge LLM Outputs from One API
Multi-model orchestration with MoA blending and circuit-breaker failover, but LiteLLM and Anthropic Batch already exist.
SlickSolve My Problem
dm118
103mo ago
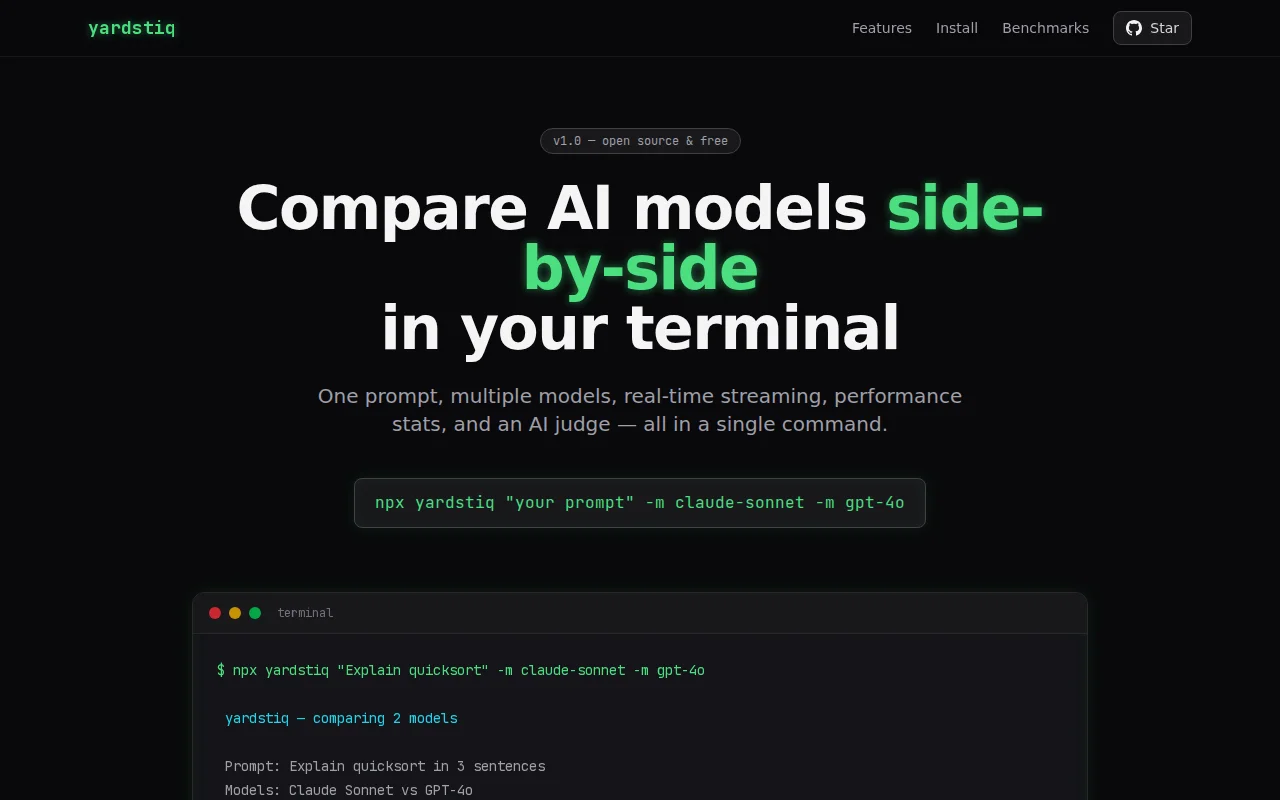
One-command model comparison with real-time streaming and performance metrics beats tab-switching.
LLM app developers, prompt engineers, model evaluators
Anthropic Workbench · OpenAI Playground · LMStudio
I built yardstiq because I got tired of the copy-paste workflow for comparing LLM responses when developing apps. Every time I wanted to see how Claude vs GPT vs Gemini handled the same prompt, I'd open three tabs, paste the same thing, and try to eyeball the differences. It's 2026 and we have 40+ models worth considering — that doesn't scale.
yardstiq is a CLI tool that sends one prompt to multiple models simultaneously and streams the responses side-by-side in your terminal. It also tracks performance metrics (time to first token, tokens/sec, cost) and optionally runs an AI judge to score the outputs.
``` npx yardstiq "Explain quicksort in 3 sentences" -m claude-sonnet -m gpt-4o ```
What it does:
- Streams responses from multiple models in parallel, rendered in columns - Shows TTFT, throughput (tok/s), token counts, and cost per request - AI judge mode: have a model evaluate and score the responses - Export to JSON, Markdown, or self-contained HTML reports - Run YAML-defined benchmark suites across models with aggregate scoring - Works with Ollama for local model comparisons (zero API cost) - Supports 40+ models via direct provider keys or Vercel AI Gateway
I built this mostly for my own workflow — picking models for different tasks, testing prompt variations, and running quick benchmarks without setting up a whole evaluation framework. It's not trying to replace serious eval platforms, just make the "which model is better for X?" question answerable in 10 seconds.
MIT licensed, written in TypeScript: https://github.com/stanleycyang/yardstiq
Happy to answer questions about the architecture or benchmarking approach.
Multi-model orchestration with MoA blending and circuit-breaker failover, but LiteLLM and Anthropic Batch already exist.
Live multi-model comparison beats static benchmarks, but AI UI generation is crowded.
One prompt, many models — that simple idea is executed with practical extras: independent conversation threads per model, full-text history/search, and bring‑your‑own API keys so you don't copy/paste. The landing page sells the daily‑driver vibe (lifetime one-time pricing is an attention grabber), but the concept itself is not novel; I'd want clearer UI for cost controls, API key security and model/version management before trusting it for heavy use.
Prompt versioning is nice, but web tools and Cursor already do side-by-side comparison.
Multilingual tokenization comparison across Arabic, Chinese, French that LangSmith ignores.
If you're burning through Claude/OpenAI credits, this is a low-friction stopgap: it classifies prompts in ~10ms and routes trivial tasks to cheaper/local models while reserving premium APIs for complex work. The agentic-task detection, reasoning-aware routing, session pinning and context-window fallback are practical touches that avoid mid-thread model bouncing and 429 failures. It isn't reinventing the space (OpenRouter and others exist), but it's focused on real-world cost tradeoffs and drop-in compatibility.