Developer Tools●●Solid
I cut LLM API bill by 55% with a Python text compressor, no AI involved
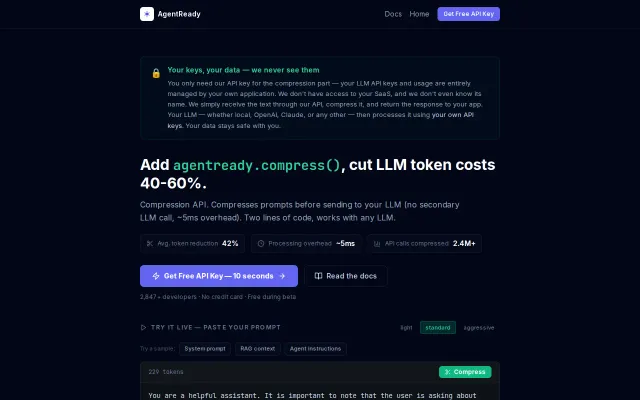
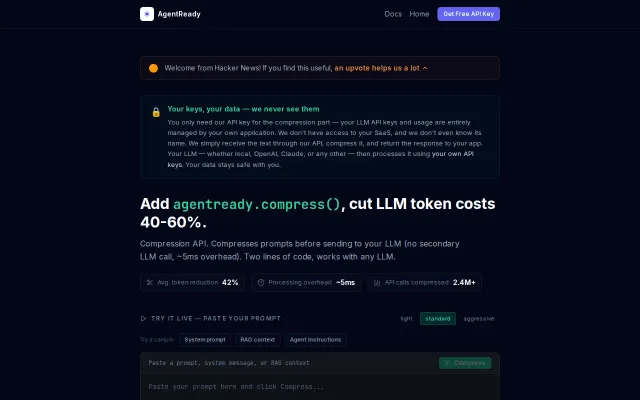
Prompt compression cuts token costs 40-60%, but it's lossless text optimization, not a novel insight.
Solve My ProblemShip It
christalingx
313mo ago
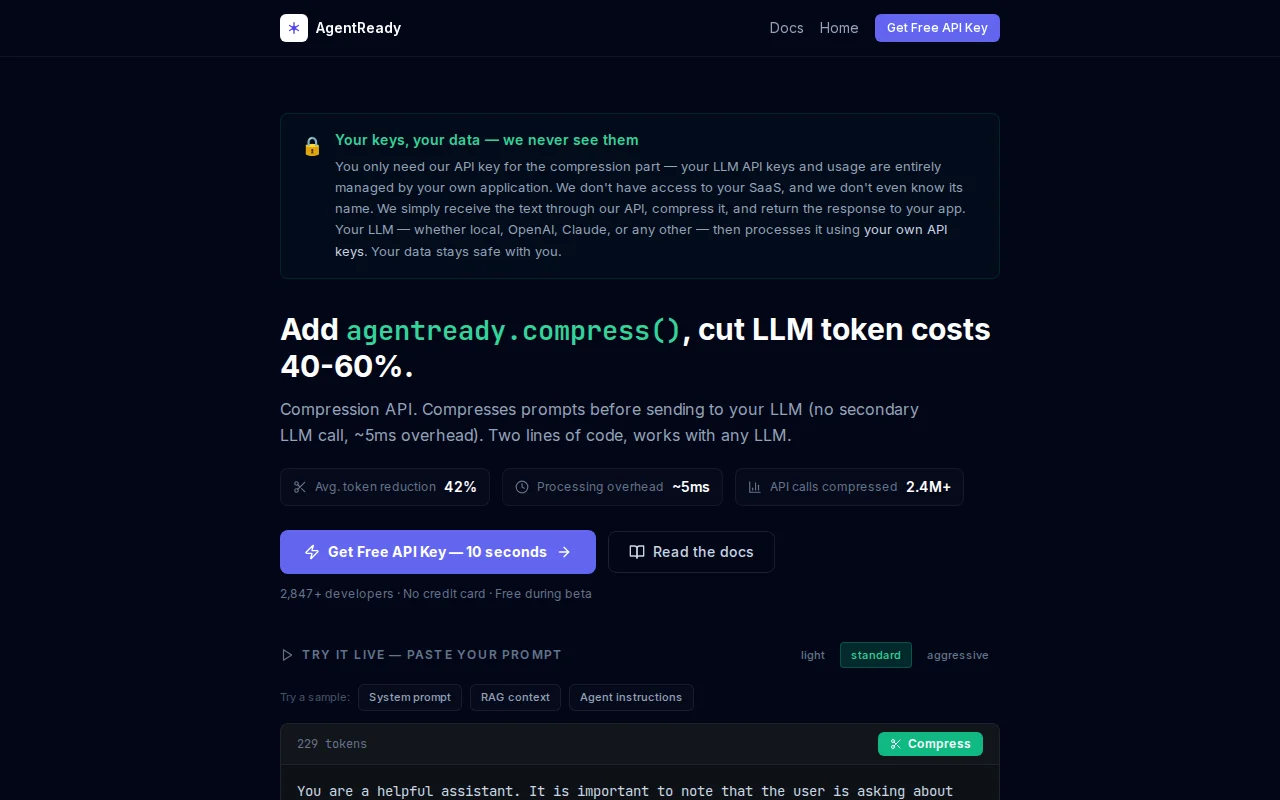
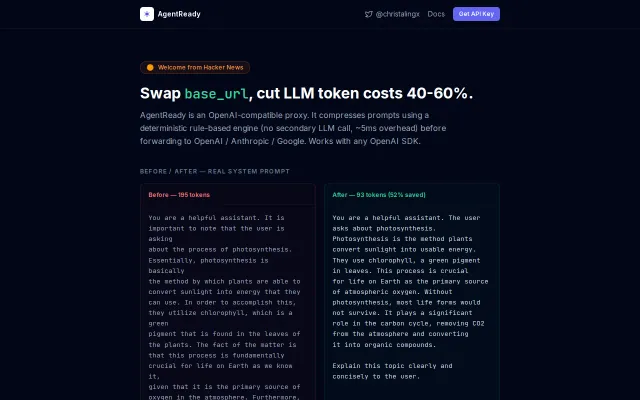
Prompt compression cuts token costs 40-60%, but prompt optimization isn't new.
LLM application developers and AI teams looking to reduce API costs
LiteLLM (LLM router/optimization) · Prompt Caching (OpenAI native feature) · Text summarization APIs (existing compression strategies)
Prompt compression cuts token costs 40-60%, but it's lossless text optimization, not a novel insight.
Prompt compression API cuts token bills 40-60%, integrates in two lines.
Drop-in proxy that cuts GPT token costs 40-60% without changing app code.
Cuts token costs 70% with receipts proving no accuracy drop on hard evals.
Deterministic prompt compression cuts tokens 50-80% without extra model calls.
Entropy-based context compression beats naive token stuffing, but the category is crowded.