AI/ML●●Solid

HighSNR – Cut length and noise from your LLM context
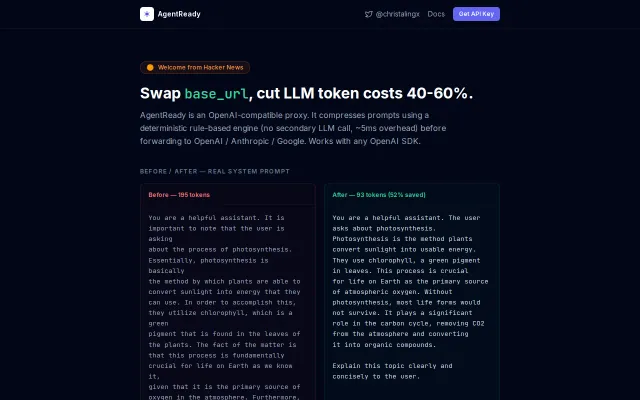
Beats full-context GPT-4o at 80% token budget with zero AI overhead.
Big BrainSolve My Problem
gskm
654mo ago
Async lightweight summarization + temporal-aware selection beats vector RAG for agent context scaling.
LangGraph and OpenClaw users, AI agent builders, teams running cost-sensitive agentic loops
Vector RAG pipelines (Langchain, LlamaIndex) · LangGraph built-in memory management · Anthropic's prompt caching
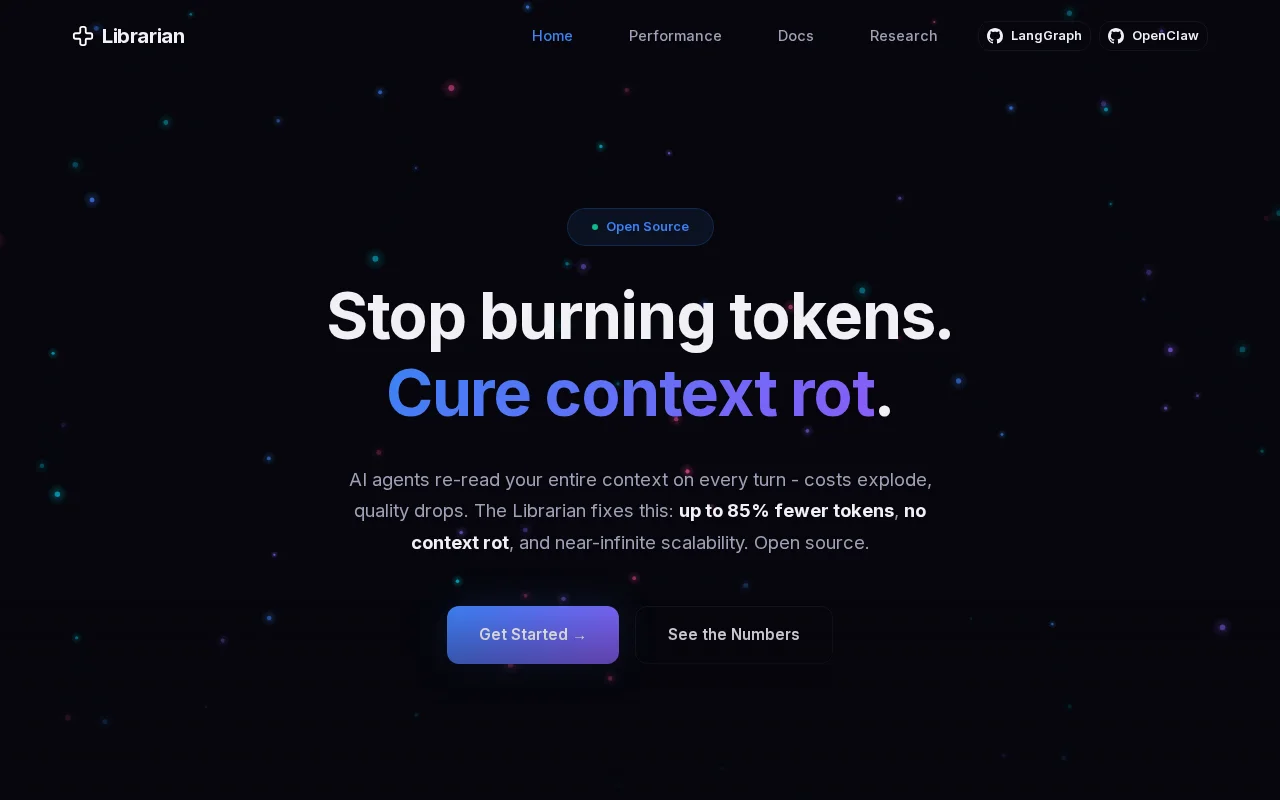
I'm building Librarian (https://uselibrarian.dev/), an open-source (MIT) context management tool that stops AI agents from burning tokens by blindly re-reading their entire conversation history on every turn.
The Problem: If you're building agentic loops in frameworks like LangGraph or OpenClaw, you hit two walls fast:
Financial Cost: Token usage scales quadratically over long conversations. Passing the whole history every time gets incredibly expensive.
Context Rot: As the context window fills up, the LLM suffers from the "Lost in the Middle" effect. Response latency spikes, and reasoning accuracy drops.
The standard workaround is vector search (RAG) over past messages, but that completely loses temporal logic and conversational dependencies.
How Librarian Fixes This: We replaced brute-force context windowing with a lightweight reasoning pipeline:
Index: After a message, a smaller model asynchronously creates a compressed summary (~100 tokens), building an index of the conversation.
Select: When a new prompt arrives, Librarian reads the summary index and reasons about which specific historical messages are actually relevant to the current turn.
Hydrate: It fetches only those selected messages and passes them to the responder.
The Results: Instead of passing 2,000+ tokens of noise, you pass a highly curated context of ~800 tokens. In our 50-turn benchmarks, this reduces token costs by up to 85% while actually increasing answer accuracy (82% vs 78% for brute-force) because the distracting noise is removed. It currently works as a drop-in integration for LangGraph and OpenClaw.
I'd love for you to check out the benchmark suite, try the integrations, and tear the methodology apart. I'll be hanging out in the comments to answer questions, debug, or hear why this approach is terrible. Thanks!
Beats full-context GPT-4o at 80% token budget with zero AI overhead.
Local tokenizer execution beats sending text to external counters.
79% token reduction for agent CLI calls with predicate pushdown and efficient output.
JinaAI and Firecrawl already solve this—Anno's token math is solid, but it's the same problem, solved.
Enterprise agent memory layer claiming 70% token savings over Zep and Mem0.
Drop-in proxy that cuts GPT token costs 40-60% without changing app code.