AI/ML●●Solid
Context Gateway – Compress agent context before it hits the LLM
SLM classifiers compress context based on tool call intent before LLM sees it.
Big BrainSolve My Problem
ivzak
97644mo ago
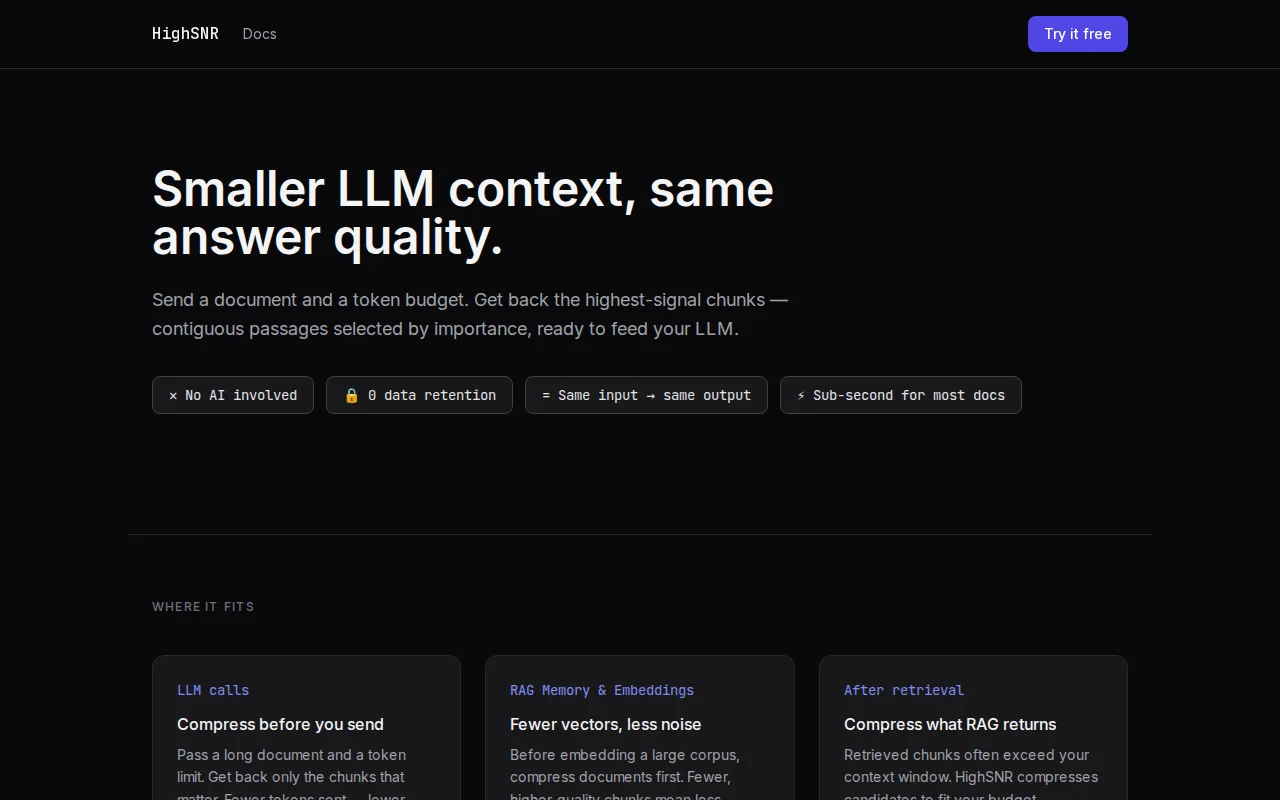
Beats full-context GPT-4o at 80% token budget with zero AI overhead.
Developers building LLM applications and RAG systems
SLM classifiers compress context based on tool call intent before LLM sees it.
Entropy-based context compression beats naive token stuffing, but the category is crowded.
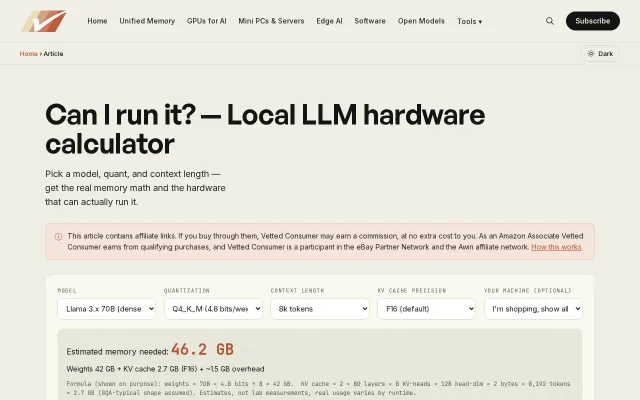
VRAM calculator with formulas visible, but many free alternatives exist.
Cuts token bills 68% by swapping full history for vector-retrieved signals.
Cuts cargo test output from 61 lines to 1 — saves 60-90% of wasted LLM tokens.
Cuts token costs 70% with receipts proving no accuracy drop on hard evals.