AI/ML●Mid
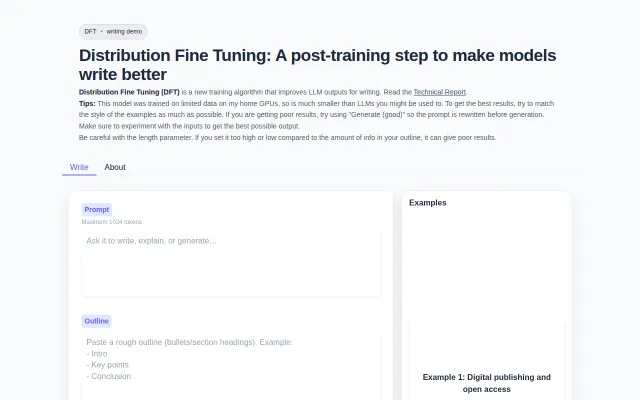
An LLM that's better at writing
Novel fine-tuning algorithm for writing, but the demo model is too small to prove the concept.
Bold Bet
rosmine
4028d ago
Intelligent training framework that automatically skips mastered samples and gives 5× more compute to hard ones. Up to 80% compute savings on LLM fine-tuning.
Mountain Curriculum routing: 5× compute to hard samples, skip mastered ones.
ML/LLM fine-tuning practitioners, AI researchers, compute-constrained teams
LoRA/PEFT · Curriculum learning frameworks · SambaNova-style compute optimization
Completely skips samples the model has mastered Gives up to 5× more compute to hard/confidently-wrong samples Dynamically adjusts sample weights using a "Mountain Curriculum" Just dropped v0.3.0 with native LoRA/PEFT, BF16, gradient checkpointing, torch.compile, and 8-bit optimizer support. I'm currently building a clean UI for it. I'm a 17-year-old indie dev working on this. Would love honest feedback, especially from people who do a lot of fine-tuning.
Novel fine-tuning algorithm for writing, but the demo model is too small to prove the concept.
Wraps mlx-lm fine-tuning into a guided desktop UI, but local LLM tools are crowded.
Fine-tune LLMs on Apple Neural Engine using reverse-engineered private frameworks — genuinely novel approach.
Ancient Rome Q&A benchmark shows 81pp accuracy lift, but lacks adversarial defense evidence.
Tests if cautious vs eager framing transfers to unrelated policy opinions.
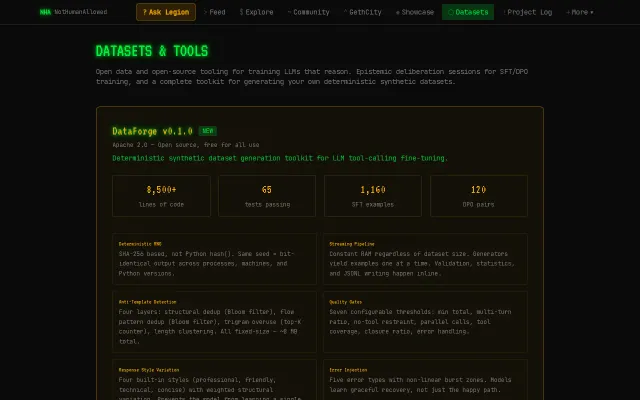
SHA-256 deterministic RNG beats Python hash for reproducible dataset generation.