Infrastructure●●●Banger
We fine-tuned an AI model for log search – Accuracy 50% to 80%
Fixes AI log search blindness by fine-tuning embeddings on operational data.
Big BrainDark HorseSolve My Problem
rkorlimarla
102mo ago
Multi-tier benchmark: Cultural grounding + Triad Engine eliminates LLM hallucination across Claude 4.6, GPT-5.2, Mistral 7B, Gemini 2.5 Pro. Raw 15-58% → 95-100% accuracy on 222 adversarial QA pairs (Ancient Rome 110 CE). Novel topological paradox detection (F1=0.939, zero-shot). Model-agnostic, in production.
Ancient Rome Q&A benchmark shows 81pp accuracy lift, but lacks adversarial defense evidence.
AI researchers, prompt engineers, teams building domain-specific LLM systems
Langchain prompt engineering · Semantic kernel · RAG systems with domain grounding
*GitHub:* https://github.com/Mysticbirdie/hallucination-elimination-be... *Paper:* https://github.com/Mysticbirdie/hallucination-elimination-be...
---
*Model-agnostic Triad Engine*: JSON domain guide → 100% accuracy across Mistral 7B/Claude/GPT—no fine-tuning.
---
## Results (222 questions, adversarial domain, Gemini 2.0 Flash judge)
| Model | Raw | + Triad | ∆ | |-------|-----|---------|---| | Mistral 7B (local) | 22.5% | *99.5%* | +77pp | | Bielik 11B (local) | 21.6% | *88.7%* | +67.1pp | | GPT-5.2 | 26.1% | *100%* | +73.9pp | | Gemini 2.5 Pro | 42.3% | *95%* | +52.7pp | | Claude 4.6 | 45.0% | *100%* | +55pp | | Perplexity Sonar (RAG) | 64.4% | *93.7%* | +29.3pp |
Perplexity has live web search—Triad still adds 29.3pp. Gemini 2.0 judge (cross-model). Claude Opus (stricter): raw Claude 14.9% → Triad 95.9%. Zero regressions.
*Beyond accuracy:* - Adversarial: Raw Claude accepts false premises 25% → Triad 5% - Consistency: Raw Claude 0% agreement across personas → Triad 100% - Concise: 2.1× shorter responses (473 vs 1,015 chars)
*Real-world (Windsurf live codebase):* | Phase | Context | Score | |-------|---------|-------| | No context | — | 40% | | Unstructured docs | — | 40% | | Triad JSON guide | — | *100%* |
---
## Triad Engine Multi-voice layer above any LLM: - λ: Character voice from domain guide - μ: Truth/false enforcement - ν: User calibration - ω: Voice compositor
*Only input*: JSON domain guide (what exists/doesn't, agents, norms). No weight changes.
Works with any LLM. Applies to medical, legal, compliance domains.
---
## Open source 222 questions, runners (Claude/GPT/Gemini/Mistral), JSON results, guide schema in repo.
Happy to answer technical questions.
Fixes AI log search blindness by fine-tuning embeddings on operational data.
Novel fine-tuning algorithm for writing, but the demo model is too small to prove the concept.
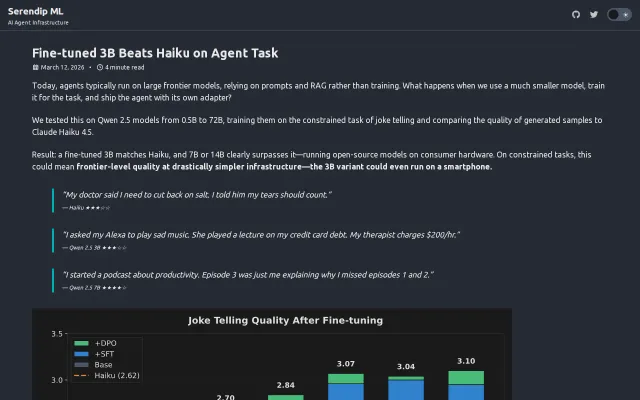
Fine-tuned 3B Qwen matches Haiku on jokes, validating small models for constrained agent tasks.
Wraps mlx-lm fine-tuning into a guided desktop UI, but local LLM tools are crowded.
Fine-tune LLMs on Apple Neural Engine using reverse-engineered private frameworks — genuinely novel approach.
Tests if cautious vs eager framing transfers to unrelated policy opinions.