AI/ML●●Solid
Pre-training, fine-tuning, and evals platform
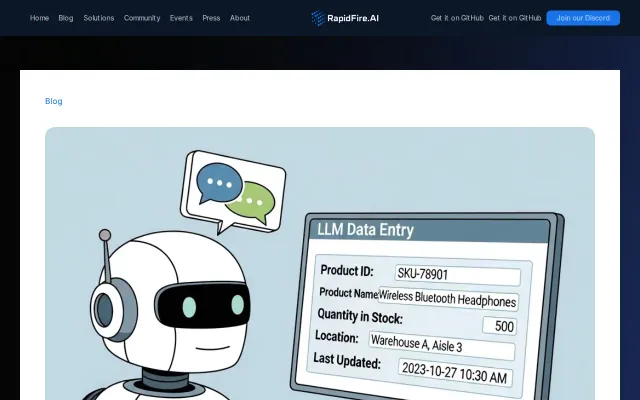
Eval-synthesize-train loop automates custom model development better than manual fine-tuning.
SlickBold Bet
oli_kitty
402mo ago
Pipeline parallelism for mixed GPUs over internet, but unproven vs established frameworks.
ML researchers and organizations with mixed GPU fleets lacking NVLink/InfiniBand
Ray Tune · DeepSpeed · vLLM
The problem:
Most distributed training assumes homogeneous GPUs and high-bandwidth interconnects (NVLink/InfiniBand). On heterogeneous fleets over standard internet, tensor/data parallel approaches become communication-bound and fragile.
What Zagora does under the hood:
- Uses pipeline-style parallelism instead of heavy tensor synchronization.
- Passes only boundary activations between stages rather than full parameter sync.
- Assigns layers proportionally to GPU capability to reduce straggler idle time.
- Uses checkpoint-based recovery to tolerate worker crashes.
- Supports adapter-based fine-tuning (e.g., QLoRA) to reduce memory pressure.
Zagora currently supports managed runs (we provision GPUs in-region) and a BYOC mode where users run workers on their own infrastructure.
Limitations:
- Full-parameter fine-tuning is not supported yet.
- It won't beat an NVLink cluster on raw throughput.
- Cross-region training is still latency-sensitive.
- Heterogeneous nodes scheduling is an ongoing tuning problem.
IMPORTANT:
I'm currently running jobs manually, so it may take some time before training starts. However, I will run every submitted job.
Link: app.zagora.ai
I'd be interested in feedback from people who've worked on distributed training at scale.
Happy to answer technical questions.
Eval-synthesize-train loop automates custom model development better than manual fine-tuning.
Shard-based scheduling cuts GPU wait time, though Ray Tune offers similar early stopping.
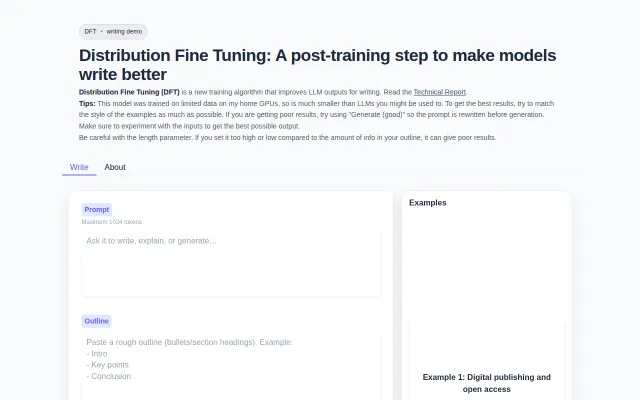
Novel fine-tuning algorithm for writing, but the demo model is too small to prove the concept.
DPO self-fine-tuning from corrections in a sea of Open WebUI clones.
BitTorrent-style distributed inference for biology LLMs across consumer GPUs.
Cool demo, but there's no actual tool to use—just a video and writeup.