Design●●Solid
The Front Page – Newspaper-style front page for Hacker News
Newspaper-style HN reader that actually respects the site's text-heavy roots.
CozyNiche Gem
stagas
29922d ago
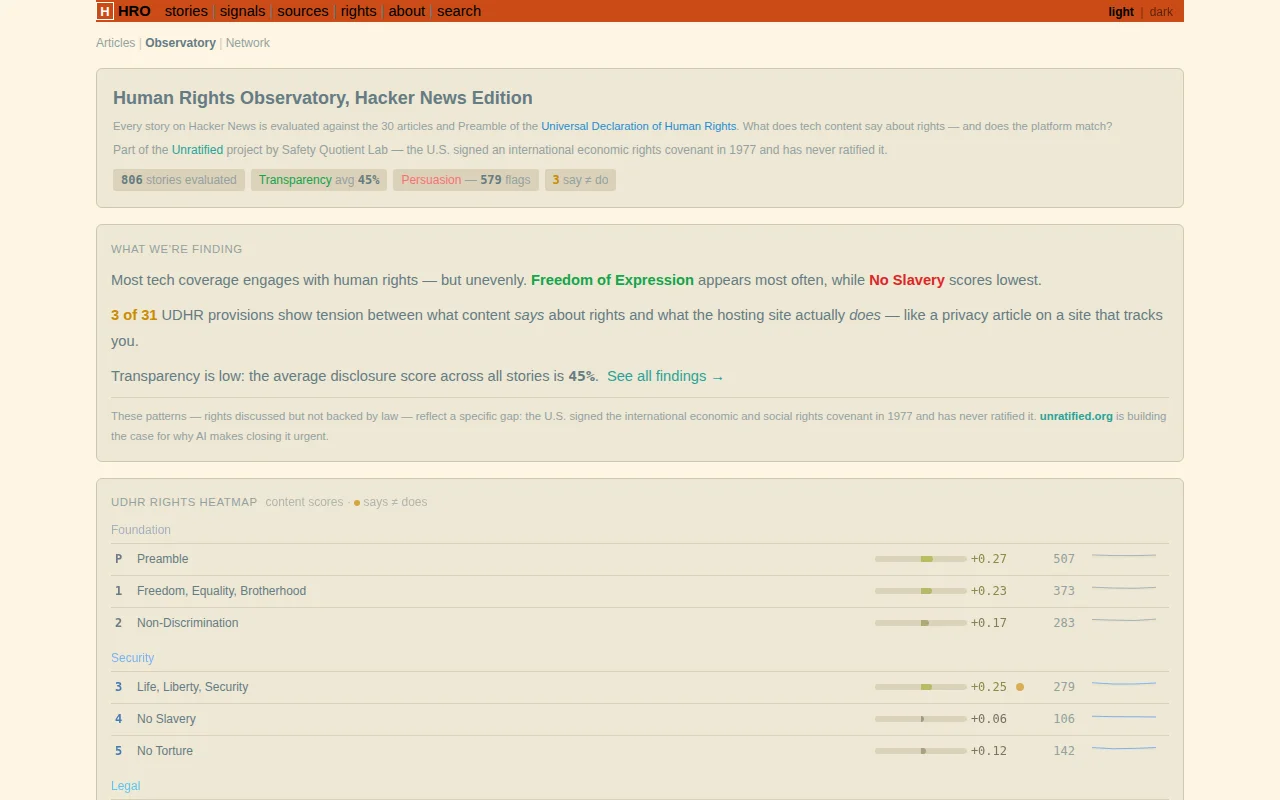
Maps 806 HN stories to UDHR articles—novel corpus, but limited generalizability beyond HN.
Human rights researchers, tech policy advocates, HN community analysts, journalists investigating platform ethics
Media Bias Fact Check · NewsGuard · Global Disinformation Index
I built Observatory to automatically evaluate Hacker News front-page stories against all 31 provisions of the UN Universal Declaration of Human Rights — starting with HN because its human-curated front page is one of the few feeds where a story's presence signals something about quality, not just virality. It runs every minute: https://observatory.unratified.org. Claude Haiku 4.5 handles full evaluations; Llama 4 Scout and Llama 3.3 70B on Workers AI run a lighter free-tier pass.
The observation that shaped the design: rights violations rarely announce themselves. An article about a company's "privacy-first approach" might appear on a site running twelve trackers. The interesting signal isn't whether an article mentions privacy — it's whether the site's infrastructure matches its words.
Each evaluation runs two parallel channels. The editorial channel scores what the content says about rights: which provisions it touches, direction, evidence strength. The structural channel scores what the site infrastructure does: tracking, paywalls, accessibility, authorship disclosure, funding transparency. The divergence — SETL (Structural-Editorial Tension Level) — is often the most revealing number. "Says one thing, does another," quantified.
Every evaluation separates observable facts from interpretive conclusions (the Fair Witness layer, same concept as fairwitness.bot — https://news.ycombinator.com/item?id=44030394). You get a facts-to-inferences ratio and can read exactly what evidence the model cited. If a score looks wrong, follow the chain and tell me where the inference fails.
Per our evaluations across 805 stories: only 65% identify their author — one in three HN stories without a named author. 18% disclose conflicts of interest. 44% assume expert knowledge (a structural note on Article 26). Tech coverage runs nearly 10× more retrospective than prospective: past harm documented extensively; prevention discussed rarely.
One story illustrates SETL best: "Half of Americans now believe that news organizations deliberately mislead them" (fortune.com, 652 HN points). Editorial: +0.30. Structural: −0.63 (paywall, tracking, no funding disclosure). SETL: 0.84. A story about why people don't trust media, from an outlet whose own infrastructure demonstrates the pattern.
The structural channel for free Llama models is noisy — 86% of scores cluster on two integers. The direction I'm exploring: TQ (Transparency Quotient) — binary, countable indicators that don't need LLM interpretation (author named? sources cited? funding disclosed?). Code is open source: https://github.com/safety-quotient-lab/observatory — the .claude/ directory has the cognitive architecture behind the build.
Find a story whose score looks wrong, open the detail page, follow the evidence chain. The most useful feedback: where the chain reaches a defensible conclusion from defensible evidence and still gets the normative call wrong. That's the failure mode I haven't solved. My background is math and psychology (undergrad), a decade in software — enough to build this, not enough to be confident the methodology is sound. Expertise in psychometrics, NLP, or human rights scholarship especially welcome. Methodology, prompts, and a 15-story calibration set are on the About page.
Thanks!
Newspaper-style HN reader that actually respects the site's text-heavy roots.
Yet another HN wrapper with no differentiation from existing readers.
Clean, read-only HN front page that strips the noise for focused reading.
Runs GPT-5 and Grok in parallel societies to test emergent social structures.
Early learning project in a crowded eval space dominated by LangSmith and Arize.
Frontier models hit 67-75% outcome accuracy but only 25-42% on process compliance.