Infrastructure●●Solid
ZSE – Single-file LLM engine with dual INT4 kernels
INT4 inference engine beats llama.cpp on VRAM, but competing against established tools.
WizardryShip It
zyoralabs
104mo ago
Train 72B models on A100-40GB via INT4 quantization, but GPTQ and bitsandbytes already exist.
ML engineers, researchers fine-tuning LLMs on consumer hardware
bitsandbytes · AutoGPTQ · GPTQ
Verified benchmarks (H200 GPU, Qwen models):
Model File Size VRAM (Inference) VRAM (+ Training) Speed 7B 5.57 GB 5.67 GB ~8 GB 37.2 tok/s 14B 9.95 GB 10.08 GB ~14 GB 20.8 tok/s 32B 19.23 GB 19.47 GB ~26 GB 10.9 tok/s 72B 41.21 GB 41.54 GB ~52 GB 6.3 tok/s What this means:
Train 7B models on RTX 3070/4070 (8GB) Train 32B models on RTX 3090/4090 (24GB) Train 70B models on A100-40GB or 2x 3090
Usage: from zse.format import load_zse_model from zse.training import LoRAConfig, add_lora_to_model
model, tokenizer, info = load_zse_model("model.zse") model = add_lora_to_model(model, LoRAConfig(rank=16, alpha=32))
# Train normally, adapter is ~25MB save_lora_adapter(model, "my_adapter.safetensors") Trainable params: 0.2% of model (12M params for 7B)
pip install zllm-zse[training]
Code: github.com/zyora-ai/zse
INT4 inference engine beats llama.cpp on VRAM, but competing against established tools.
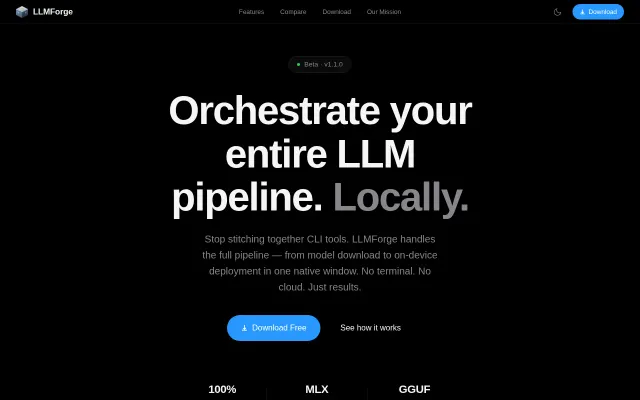
Full LLM pipeline in one window when LM Studio only does inference.
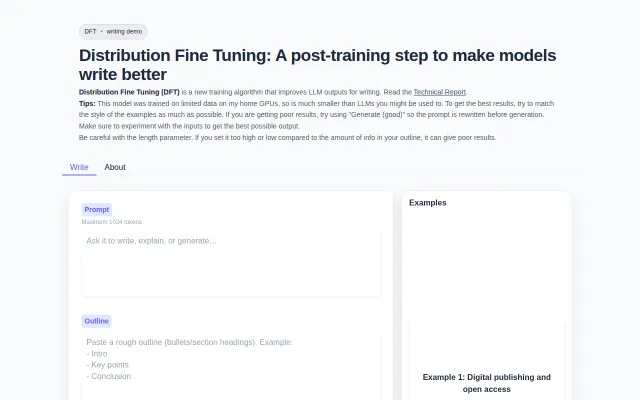
Novel fine-tuning algorithm for writing, but the demo model is too small to prove the concept.
Wraps mlx-lm fine-tuning into a guided desktop UI, but local LLM tools are crowded.
Fine-tune LLMs on Apple Neural Engine using reverse-engineered private frameworks — genuinely novel approach.
Ancient Rome Q&A benchmark shows 81pp accuracy lift, but lacks adversarial defense evidence.