AI/ML●●●Banger
LLM Sycophancy Benchmark: Opposite-Narrator Contradictions
Opposite-narrator test catches models agreeing with both sides of same dispute.
Big BrainDark Horse
zone411
304mo ago

Clever benchmark exposing LLM tokenization weakness on ASCII art, but narrow domain.
AI researchers, LLM practitioners, musicians interested in AI capabilities and limitations.
MMLU · ARC · Harness
182 test cases, 4 tunings, 14 models via OpenRouter. Two open-weight Qwen models from Alibaba crushed everything else (83.5%), while most "flagship" models scored below 50%. MiniMax M2.5 scored worse than random guessing.
Everything is open source: https://github.com/jmcapra/FretBench
I'm curious whether the performance gap is related to tokenisation of ASCII art — if anyone has insights on how different tokenisers handle grid-structured text, I'd love to hear it.
Opposite-narrator test catches models agreeing with both sides of same dispute.
Clever use of bar numbers to deduplicate frames instead of just timestamp sampling.
Postman for local LLMs with LLM-as-Judge and Elo ratings built in.
Finally exposes vendor BS by ranking scrapers on hard targets like Amazon and Cloudflare.
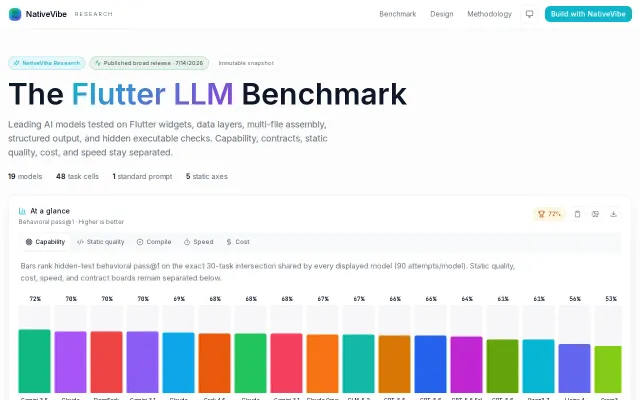
Checks blur events and DevTools heuristics before HackerRank flags your session.
Hidden executable tests separate working code from static analysis fluff better than HumanEval.