AI/ML●●●Banger
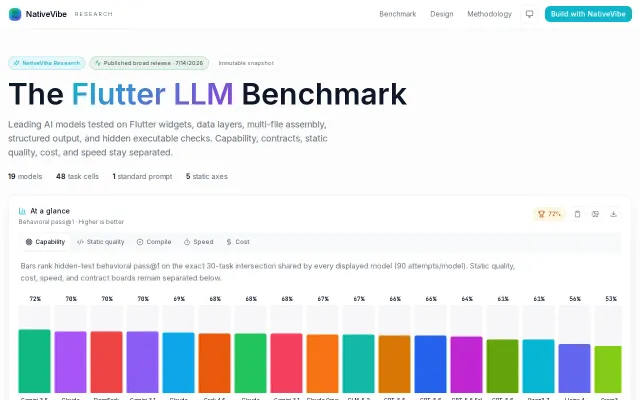
Ranking 19 LLMs on Flutter code by compile pass and hidden-test pass 1
Hidden executable tests separate working code from static analysis fluff better than HumanEval.
Big BrainDark Horse
GeorgiKadrev
203d ago
A GUI-first evaluation workbench for local LLMs running on Ollama. Build personal test suites, run sequential evaluations across installed models, visualize results through dashboards, and make keep-or-delete decisions. Think "Postman for local LLM evaluation."
Postman for local LLMs with LLM-as-Judge and Elo ratings built in.
Developers testing local LLMs, Ollama users, AI researchers
LangSmith · MLflow · LM Evaluation Harness
Hidden executable tests separate working code from static analysis fluff better than HumanEval.
Task-specific LLM benchmarking beats generic leaderboards that ignore your actual workload.
Phoenix LiveView embedding beats switching to LangSmith for Elixir teams.
AST-based validation for function calling tests, but BFCL already covers this ground.
Open test suites in the repo when LeetCode keeps theirs closed.
Opposite-narrator test catches models agreeing with both sides of same dispute.