AI/ML●●●Banger
PureBee – A software-defined GPU running Llama 3.2 1B at 3.6 tok/SEC
Pure math beats silicon: full LLM inference via auditable WASM+SIMD, zero compiler toolchain.
WizardryBig BrainZero to One
benryanx
364mo ago
26B model at 124 tok/s on CPU by compressing the output head, not the experts.
ML engineers, robotics developers, edge AI practitioners
llama.cpp · MLX · Off Grid AI
Pure math beats silicon: full LLM inference via auditable WASM+SIMD, zero compiler toolchain.
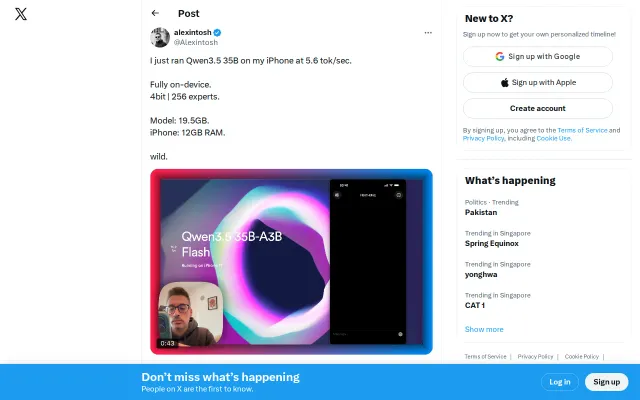
Runs 19.5GB Qwen3.5 on 12GB RAM iPhone via memory swapping.
Metal GPU stress testing in terminal, but is the workload realistic for benchmarking?
One-command benchmark suite comparing Ollama and XGBoost performance with a shared Streamlit dashboard.
33x speedup over mmap for 70B on RTX 3090, but still 0.2 tok/s vs vLLM's 30+ tok/s.
NumPy API on WebGPU with zero shader writing beats TensorFlow.js bloat for compute.