AI/ML●●Solid
35B MoE LLM and other models locally on an old AMD crypto APU (BC250)
Kernel ttm.pages_limit workaround unlocks 16GB UMA for Vulkan inference on repurposed crypto hardware.
Dark HorseNiche Gem
akandr
202mo ago
AMD BC-250 (PS5 APU) setup guide — Ollama + Vulkan inference, poor man's AI assistant via Signal, stable-diffusion.cpp image generation
Clever hardware hack but this is a config guide, not a shipped tool.
Hobbyists running local LLMs on budget hardware
Ollama · llama.cpp · stable-diffusion.cpp
Kernel ttm.pages_limit workaround unlocks 16GB UMA for Vulkan inference on repurposed crypto hardware.
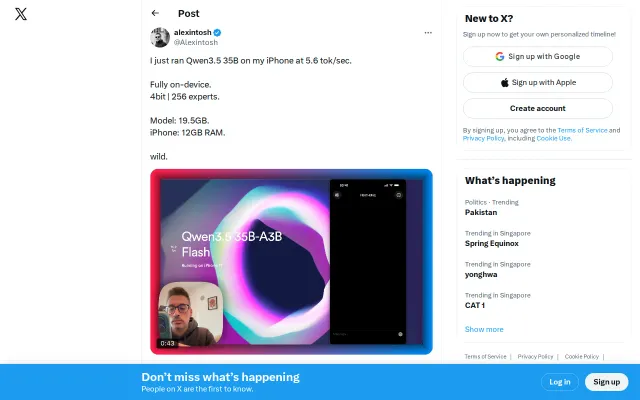
Runs 19.5GB Qwen3.5 on 12GB RAM iPhone via memory swapping.
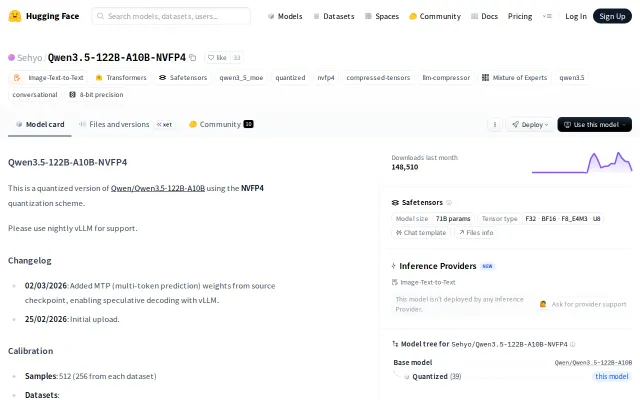
Bypasses NVIDIA's artificial FP4 lock—122B MoE on single desktop GPU at 31 tok/s.
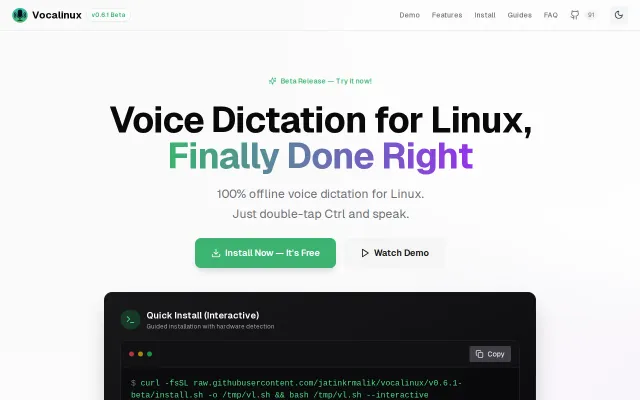
Linux finally gets offline voice typing; Ctrl-tap + Vulkan GPU support vs cloud-dependent alternatives.
Native Swift inference with SSD streaming runs 100B MoE models without kernel panics.
Temporary public endpoint for Qwen3.6-35B quant on a spot instance.