Developer Tools●●●Banger
Tracecore: Benchmark AI Agents on Deterministic Coding Tasks
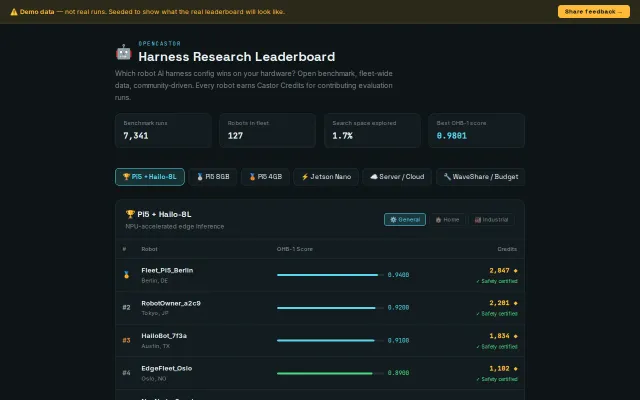
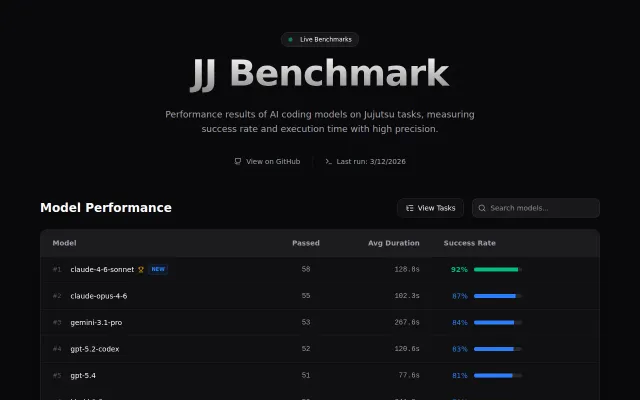
Deterministic agent benchmarking with strict validation—unlike SWE-Bench, measures whether agents actually operate.
Solve My ProblemWizardryNiche Gem
extra_cookin
103mo ago