AI/ML●●Solid
Running Gemma 4 on an iPhone 13 Pro
Clean Swift wrapper for Gemma 4 with vision and audio on iPhone.
Niche GemShip It
dengjiuhong
101mo ago
⚡ Native MLX Swift LLM inference server for Apple Silicon. OpenAI-compatible API, SSD streaming for 100B+ MoE models, TurboQuant KV cache compression, MACOS + iOS iPhone app.
Native Swift inference with SSD streaming runs 100B MoE models without kernel panics.
Apple Silicon developers, local LLM enthusiasts, iOS engineers
Ollama · llama.cpp · LM Studio
Clean Swift wrapper for Gemma 4 with vision and audio on iPhone.
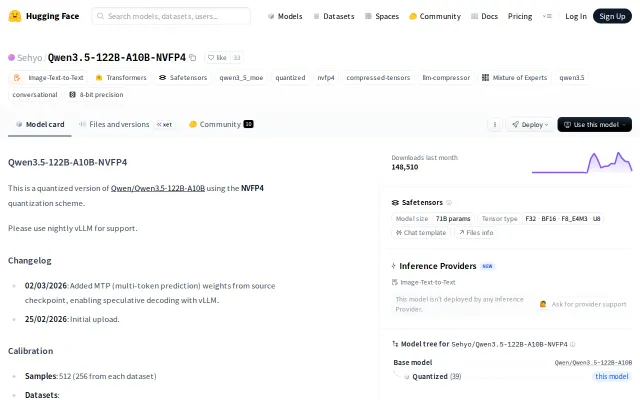
Bypasses NVIDIA's artificial FP4 lock—122B MoE on single desktop GPU at 31 tok/s.
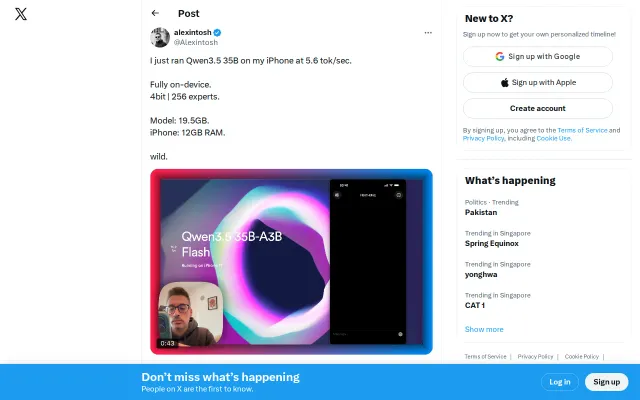
Runs 19.5GB Qwen3.5 on 12GB RAM iPhone via memory swapping.
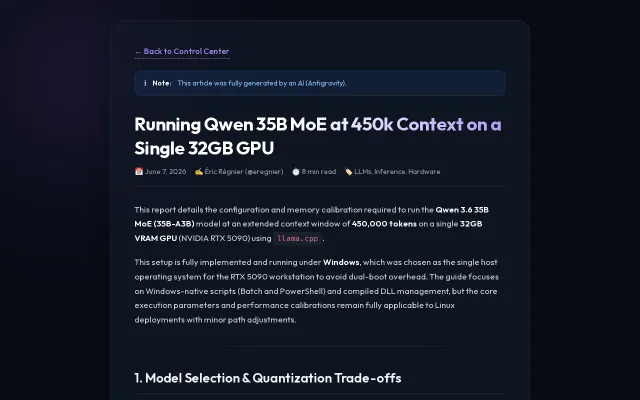
450k context on 32GB VRAM using turboquant KV cache compression.
Yet another font manager when Font Book and iOS already handle this.
BFS-layered 3D codebase viz solves force-directed chaos; works in browser for instant PR review.