AI/ML●●●Banger
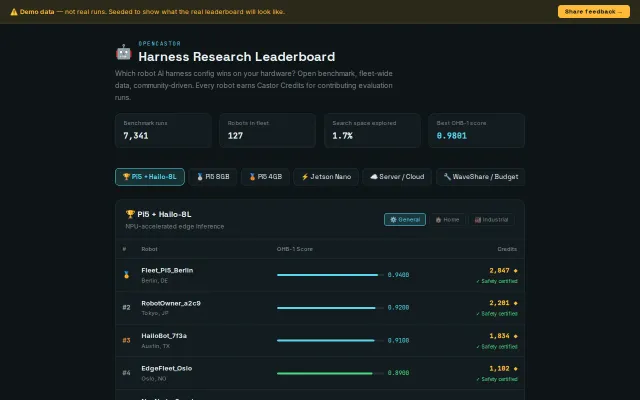
OpenCastor Agent Harness Evaluator Leaderboard
263k config search space benchmarked across robot fleets—nothing like this exists for robotics AI.
Zero to OneBig BrainNiche Gem
craigm26
312mo ago
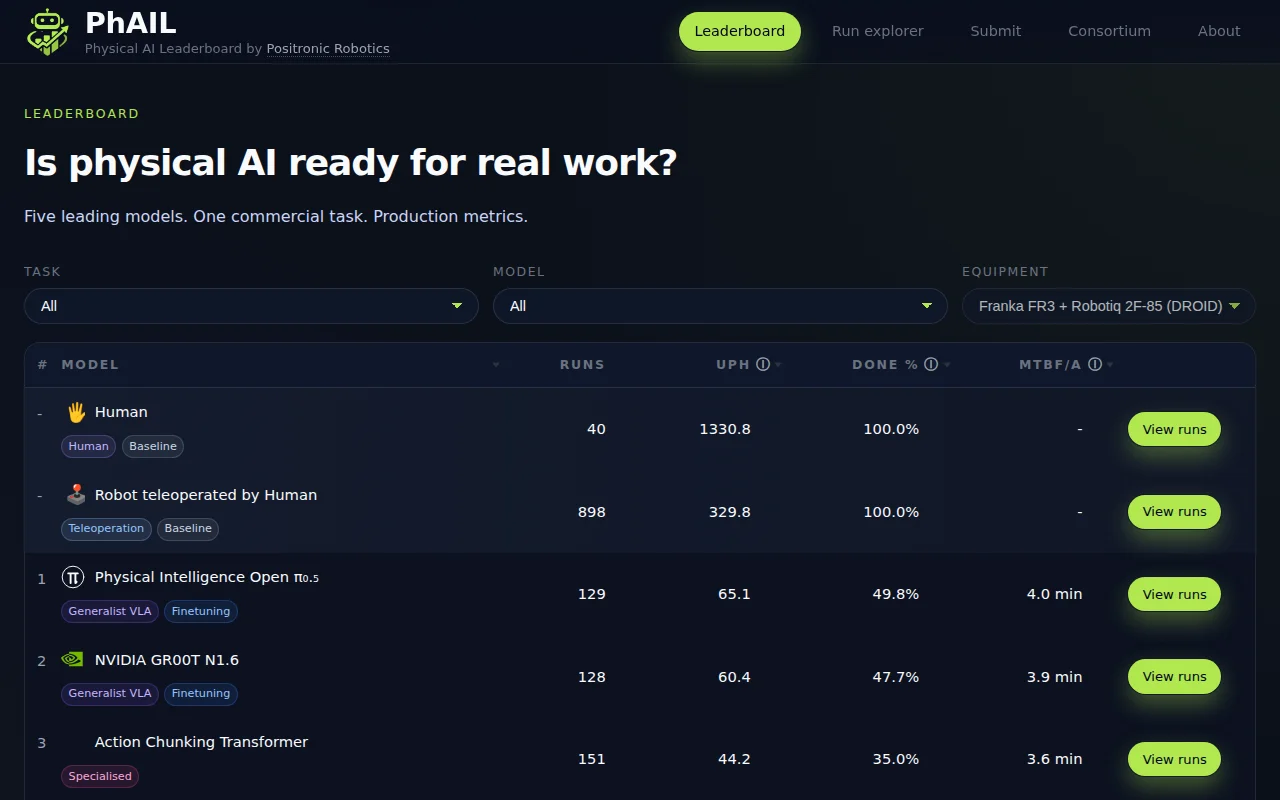
Real-robot production benchmarks proving AI is still 20x slower than humans.
Robotics engineers, AI researchers, Automation investors
Papers With Code · HELM · Robotics Challenge Leaderboards
263k config search space benchmarked across robot fleets—nothing like this exists for robotics AI.
Pre-2022 human posts vs AI models in a crowd-sourced detection benchmark.
Clever benchmark exposing LLM tokenization weakness on ASCII art, but narrow domain.
Side-by-side model comparison eliminates guessing which speech engine fits your hardware.
Side-swapped debate matchups expose model weaknesses standard benchmarks miss.
Benchmarks OpenCode models locally, but lacks preloaded datasets and only works with configured OpenAI-compatible APIs.