AI/ML●Mid
100% LLM accuracy–no fine-tuning, JSON only
Ancient Rome Q&A benchmark shows 81pp accuracy lift, but lacks adversarial defense evidence.
Big Brain
MysticBirdie
223mo ago
Matrix Renderer for LLMs — 70% → 100% accuracy. The problem isn't the model, it's the representation.
Ten-question benchmark doesn't prove 70%→100% claims when code interpreters already do this.
Developers building LLM agents and AI tooling
Cursor Agent Mode · Continue.dev · LangChain Tools
Ancient Rome Q&A benchmark shows 81pp accuracy lift, but lacks adversarial defense evidence.
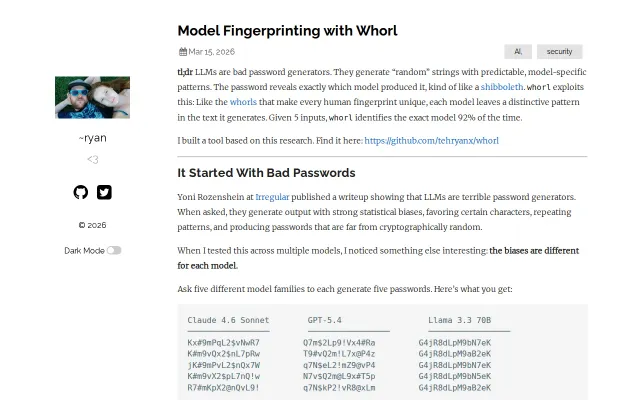
Identifies LLM models by password bias patterns when they refuse to tell you.
First linter + benchmark for MCP servers; catches vague schemas before LLMs pick wrong tools.
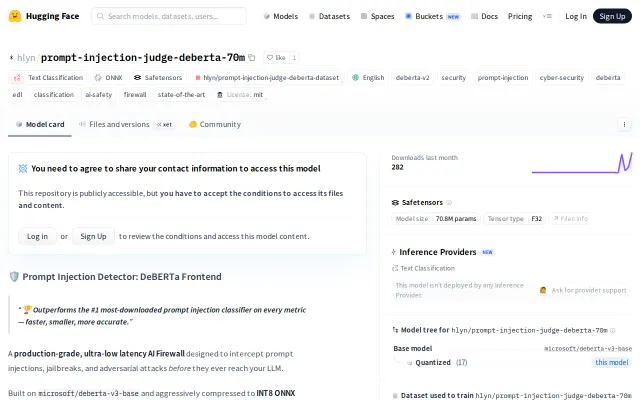
Beats ProtectAI by 19% accuracy and runs 9x smaller on CPU.
Agent loop proofreading evals where HELM and LMSys are too generic.
Anthropic research paper, not a Show HN project — link doesn't match the described multi-Claude system.