AI/ML●●Solid

FretBench – I tested 14 LLMs on reading guitar tabs. Most failed
Clever benchmark exposing LLM tokenization weakness on ASCII art, but narrow domain.
Big BrainNiche Gem
jmcapra
104mo ago
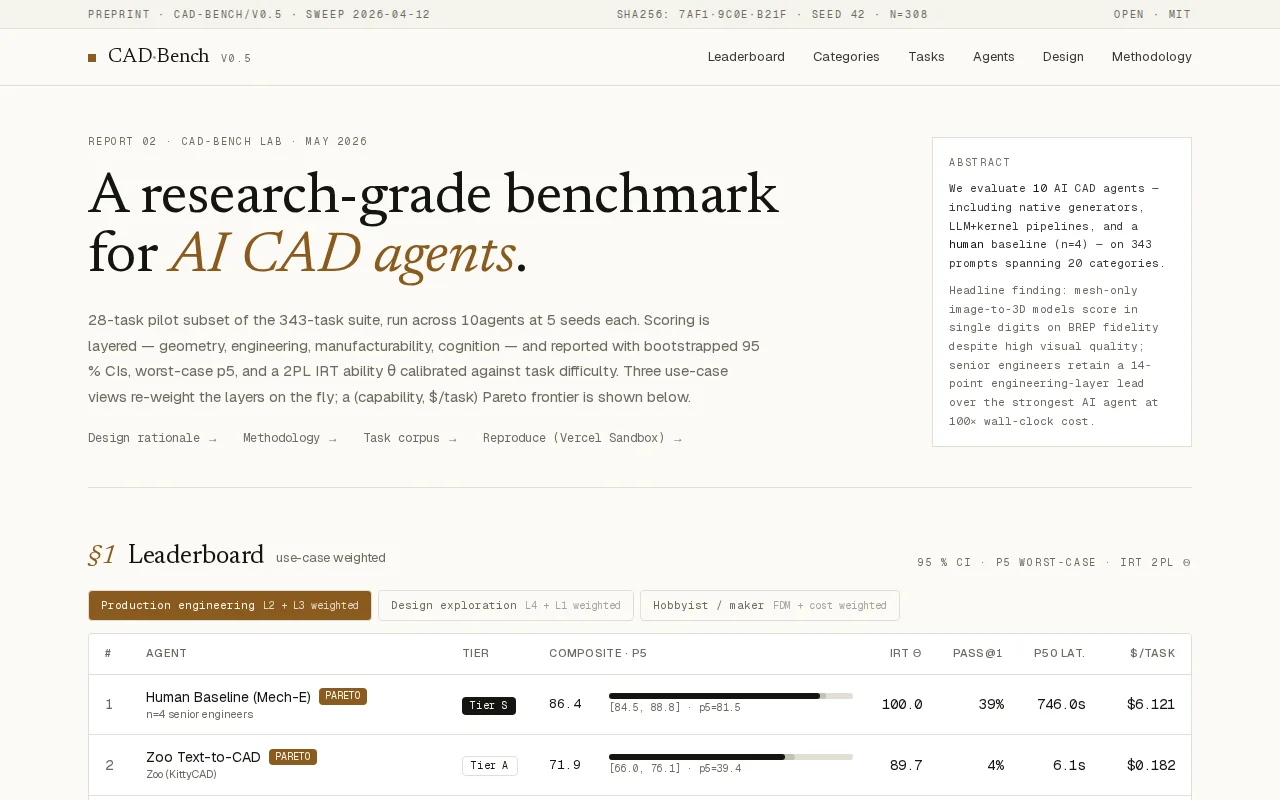
Proves mesh-to-BREP failure modes with IRT-calibrated scores across 28-task pilot suite.
CAD software developers, AI researchers, mechanical engineers
HumanEval · BigCodeBench · SWE-bench
Clever benchmark exposing LLM tokenization weakness on ASCII art, but narrow domain.
Finally exposes vendor BS by ranking scrapers on hard targets like Amazon and Cloudflare.
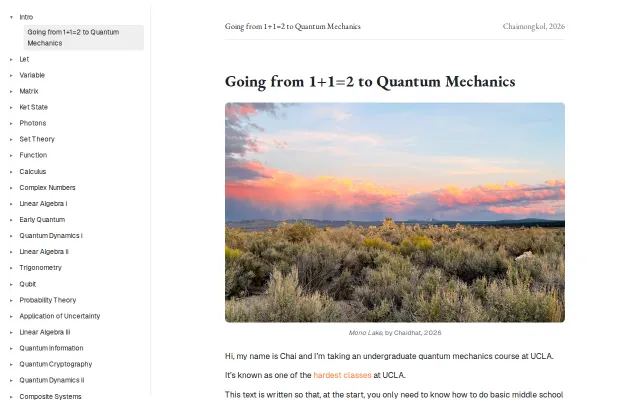
Ambitious curriculum bridging basic arithmetic to quantum mechanics without skipping steps.
Editable BREP output beats mesh generators—download the code and keep building.
Another browser CAD, but v0.0.1 lacks features to compete with Onshape.
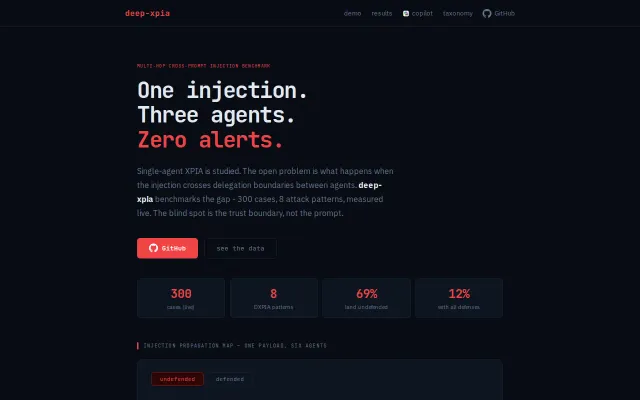
Maps cross-agent injection attacks to real Copilot CVEs with live measurements.