AI/ML●●●Banger
AI image models hallucinate history, we built a method to fix it it
Naive prompts hallucinate history; structured knowledge injection raises accuracy from 12.5% to 83.3%.
Big BrainWizardrySolve My Problem
MysticBirdie
122mo ago
Code3DBench: Single-Image to Executable Low-Poly 3D Code Generation
Benchmarks AI generating Three.js code from images, not just static mesh outputs.
AI researchers, 3D developers, ML engineers
HELM · BigBench · EvalPlus
Naive prompts hallucinate history; structured knowledge injection raises accuracy from 12.5% to 83.3%.
Interactive DuckDB-WASM benchmark beats static leaderboards for agentic SQL eval.
Daily CI/CD health checks for Pollinations.ai models, but anyone can do this with cron.
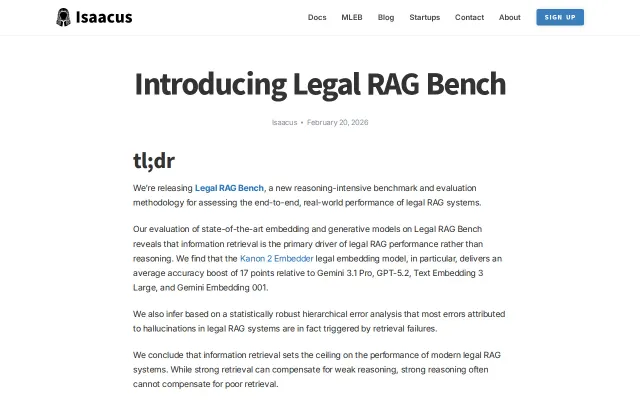
Legal RAG benchmark revealing embedding quality > LLM choice by 19-point margin.
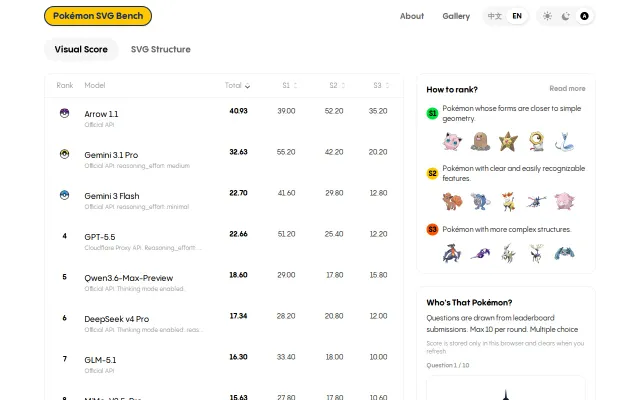
Finally, a benchmark that uses Pokémon to test if models understand complex geometry.
Unified video and image model trained from scratch on just 128 GPUs.