AI/ML●●●Banger
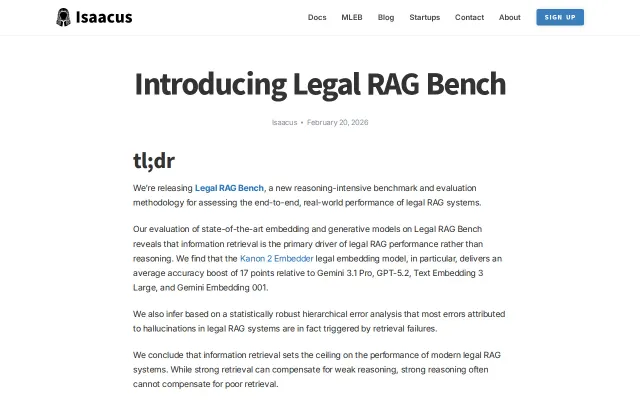
Legal RAG Bench
Legal RAG benchmark revealing embedding quality > LLM choice by 19-point margin.
Big BrainNiche GemSolve My Problem
beowa
413mo ago
Benchmark measuring historical accuracy of AI-generated images. 24 image pairs (3 characters × 8 scenes) set in Rome 110 CE, comparing naive prompts vs culturally-grounded prompts. Blinded A/B evaluation shows structured knowledge injection produces 5x more historically accurate images. Includes prompts, evaluation rubric, and reproducible pipeline
Naive prompts hallucinate history; structured knowledge injection raises accuracy from 12.5% to 83.3%.
AI researchers, prompt engineers, computer vision teams
Anthropic's Evals framework · OpenAI's benchmarks for prompt engineering quality
Results:
RAW (naive prompt): 12.5% historically accurate TRIAD (grounded prompt): 83.3% historically accurate In 23 of 24 pairs, the grounded image was judged more accurate In 0 of 24 pairs was the naive image judged better The key insight for prompt engineers: image models silently drop historical terms they don't recognize. "dextrarum iunctio handshake" produces nothing useful. "two men clasping right hands wrist-to-wrist, elbows raised" works. Visual translation, not historical terminology.
The full benchmark — all 48 images, prompts, evaluation data, and reproducible pipeline — is open source. You can re-run the blinded evaluation yourself with a free Gemini API key.
Repo: https://github.com/Mysticbirdie/image-cultural-accuracy-benc...
Paper: https://github.com/Mysticbirdie/image-cultural-accuracy-benc...
Legal RAG benchmark revealing embedding quality > LLM choice by 19-point margin.
First benchmark testing structured requirements on complex greenfield agent tasks.
Tests workflow + tool + model together, not just model capability like SWE-bench.
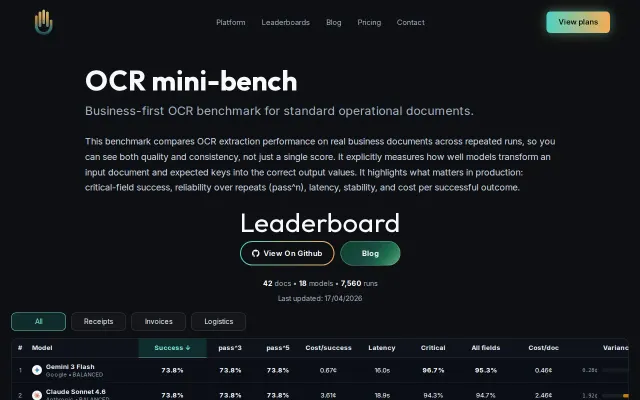
7,560 runs proving cheaper models beat expensive ones on production OCR tasks.
Measures AI agent security in dollars to exploit, not just binary pass or fail rates.
Opposite-narrator test catches models agreeing with both sides of same dispute.