AI/ML●Mid
I benchmarked Gemma 4 E2B – the 2B model beat the 12B on multi-turn
2B model beats 12B on some tasks, saving hardware costs for edge deployment.
Big BrainNiche Gem
mailharishin
812mo ago
An automated testing suite evaluates different AI image generation models from Pollinations.ai.
Daily CI/CD health checks for Pollinations.ai models, but anyone can do this with cron.
ML engineers, API maintainers testing generative models
GitHub Actions (built-in CI/CD) · Datadog API monitoring · PostMan API testing suites
2B model beats 12B on some tasks, saving hardware costs for edge deployment.
Hourly quota resets beat daily limits, but it's still just another AI wrapper plugin.
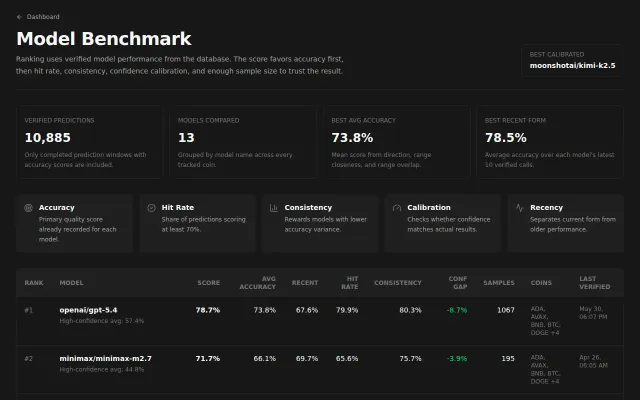
Polished dashboard tracking AI crypto predictions that fundamentally cannot work reliably.
Side-by-side model comparison eliminates guessing which speech engine fits your hardware.
Task-specific LLM benchmarking beats generic leaderboards that ignore your actual workload.
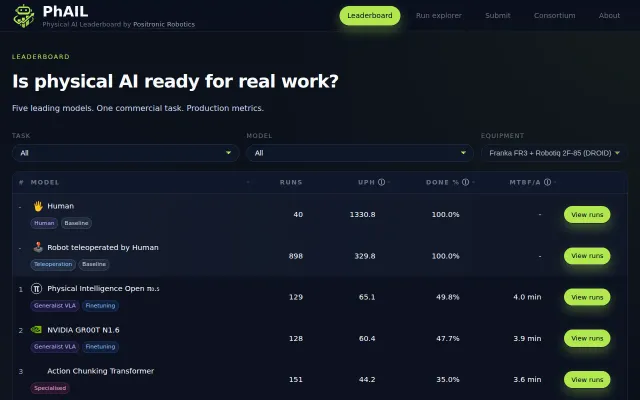
Real-robot production benchmarks proving AI is still 20x slower than humans.