AI/ML●Mid
Ebbforge - 10M agent Rust swarm engine, 8 fundamental benchmarks
Rust swarm vs LLM agents is clever positioning, but benchmarks are self-designed and lack third-party validation.
Big BrainWizardry
agent-world
214mo ago
Benchmark local LLM inference speed (tokens/sec) on your own hardware — llama.cpp native + cloud APIs, 124-model catalog, optimal-quant picker, and an MCP serve mode.
One-click LLM benchmarking with real tok/s metrics when llama.cpp requires manual setup.
Developers running local LLMs, hardware enthusiasts
llama.cpp benchmarks · LM Studio · Ollama
Rust swarm vs LLM agents is clever positioning, but benchmarks are self-designed and lack third-party validation.
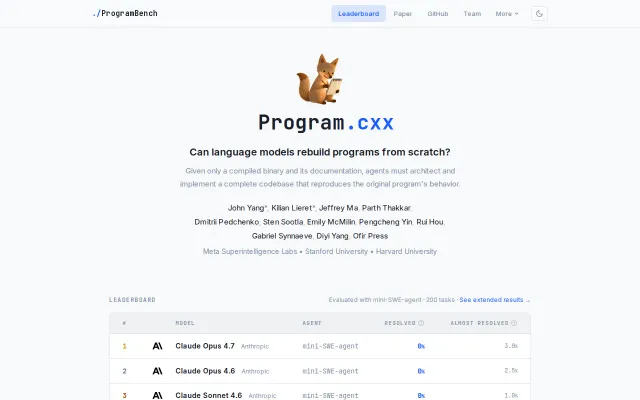
Agents fail completely at rebuilding binaries from scratch without source code.
Opposite-narrator test catches models agreeing with both sides of same dispute.
Direct MFT parsing beats Everything by 2.8× in 30/30 benchmark cells.
Side-swapped debate matchups expose model weaknesses standard benchmarks miss.
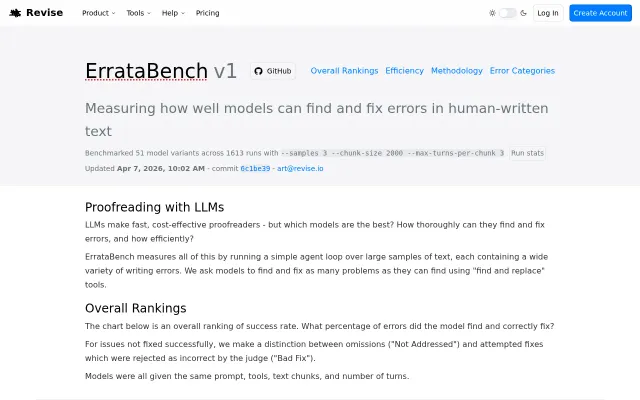
51 models, 1613 runs, $558 spent — finally proofreading benchmarks with real numbers.