AI/ML●●●Banger
AI image models hallucinate history, we built a method to fix it it
Naive prompts hallucinate history; structured knowledge injection raises accuracy from 12.5% to 83.3%.
Big BrainWizardrySolve My Problem
MysticBirdie
123mo ago
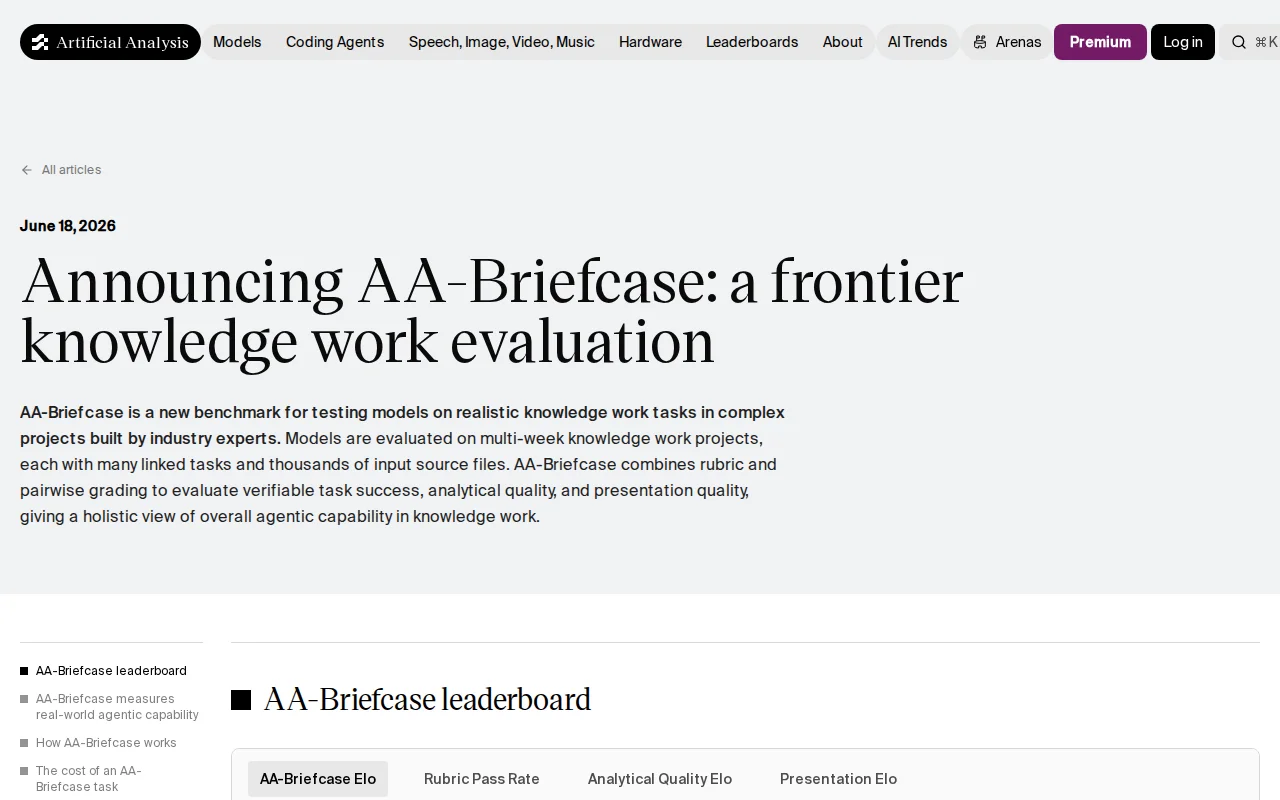
Multi-week project evals beat single-task benchmarks for measuring real agentic capability.
AI researchers, ML engineers evaluating agentic systems
SWE-bench · GAIA · AgentBench
Naive prompts hallucinate history; structured knowledge injection raises accuracy from 12.5% to 83.3%.
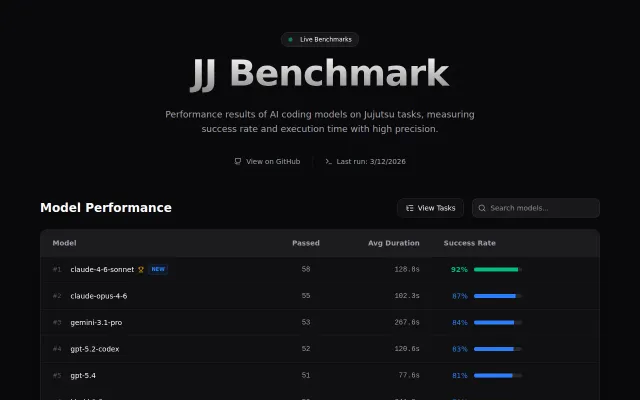
AI benchmarking for jj CLI when LMSys and HuggingFace already dominate the space.
Interactive DuckDB-WASM benchmark beats static leaderboards for agentic SQL eval.
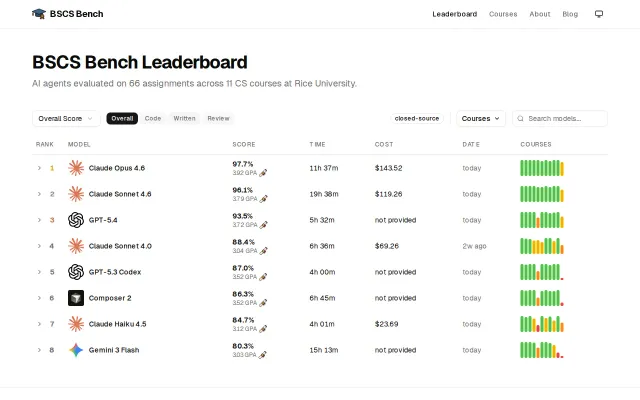
Real CS coursework beats synthetic coding benchmarks for model evaluation.
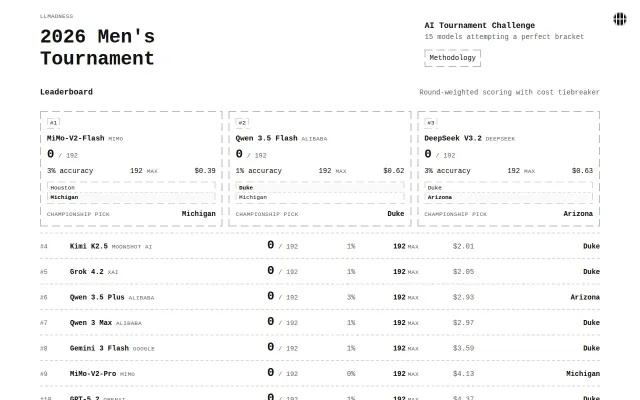
Claude Opus spent $59.55 versus MiMo-Flash at $0.39 for identical bracket predictions.
90.3 BrowseComp score with verification-centric model architecture.