AI/ML●●●Banger
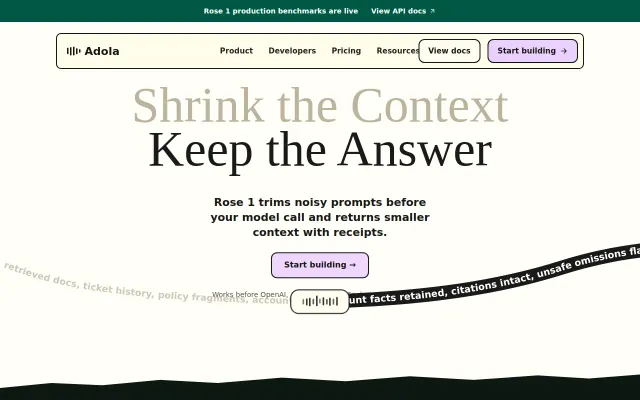
Reducing LLM input tokens by 70%
Cuts token costs 70% with receipts proving no accuracy drop on hard evals.
Zero to OneSolve My Problem
Jbunga
56331mo ago
Reproducible benchmark results for Compresh: episodic-memory recall + compression fidelity, scored with each benchmark's own method and an independent judge.
Matches full-context recall at 1% tokens, but chronological ordering still lags behind naive RAG.
ML engineers and researchers working on LLM context optimization
Needle In A Haystack · RAGAS · LongBench
Cuts token costs 70% with receipts proving no accuracy drop on hard evals.
Entropy-based context compression beats naive token stuffing, but the category is crowded.
Slash agent token costs 164x with hook reducers and persistent daemon state.
Reverse proxy lets Claude compress its own context before hitting the API.
Heuristic DOM matching cuts LLM calls, saving 89% on tokens compared to naive context stuffing.
60x compression for AI context, but handoff format viability depends on LLM adoption.
