Developer Tools●●Solid
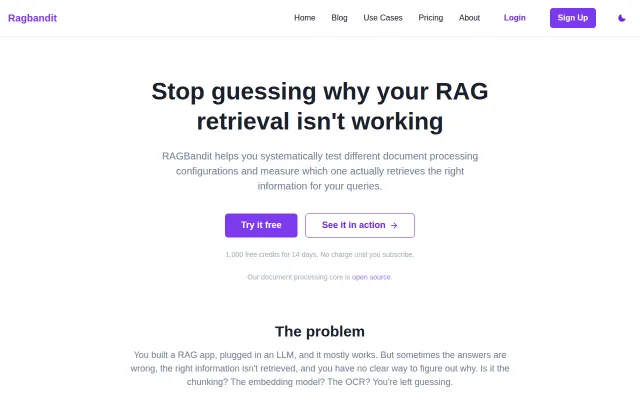
Rust-powered document chunker for RAG – 40x faster, O(1) memory
Rust core beats LangChain's Python bottleneck, but chunking alone won't move the needle.
WizardryShip It
kriralabs
1433mo ago
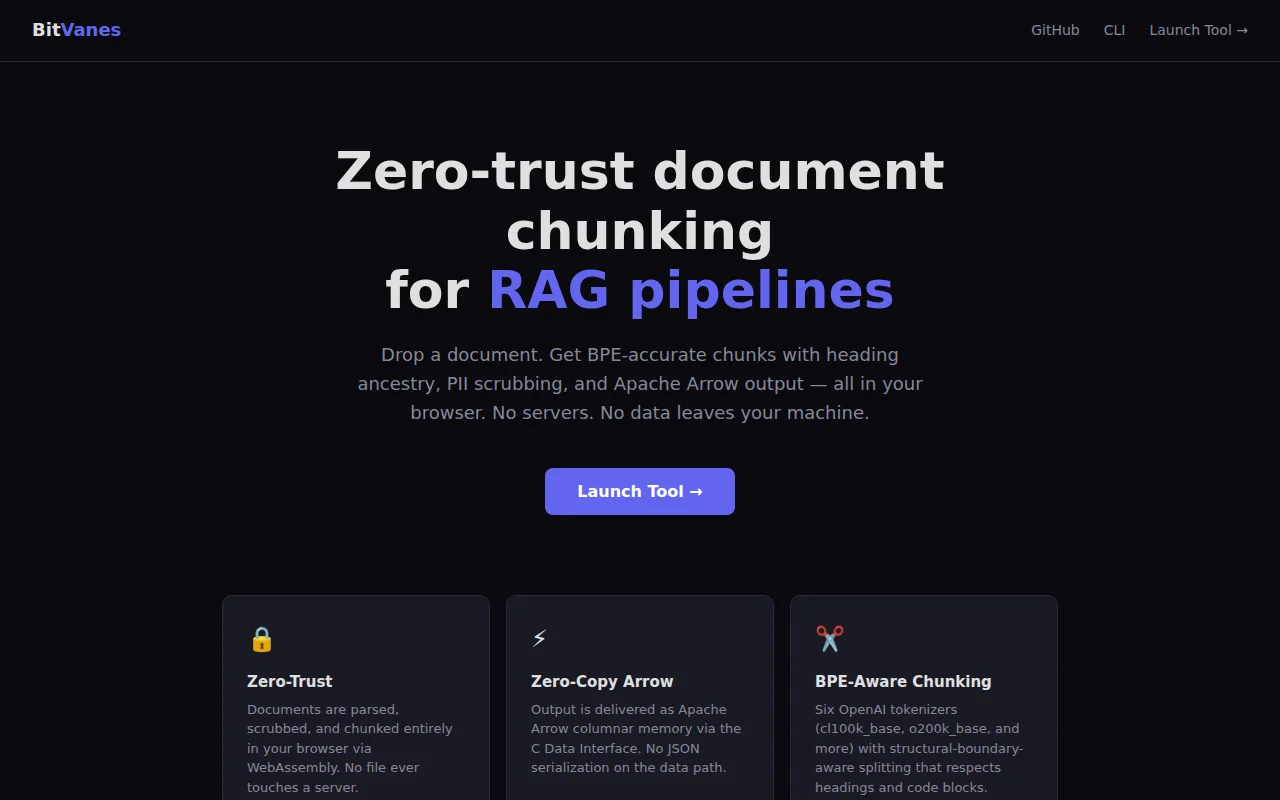
Runs entire RAG preprocessing in-browser via WASM — no data ever leaves your machine.
Developers building privacy-sensitive RAG pipelines
Unstructured · LlamaIndex · LangChain
I'd love to get your thoughts on the architecture, particularly around using Arrow (it's my first time using AA, I'm coming from capnp), or the Rust-to-JS design for pdfs to keep the wasm package reasonable.
I'd like to crates the package once I've had some people kick the tires and I get it ironed out.
Rust core beats LangChain's Python bottleneck, but chunking alone won't move the needle.
Yet another RAG security layer when Lakera Guard already exists.
Finally: XLOOKUP, FILTER, dynamic arrays in Python—openpyxl can't, xlcalc won't.
LLM-as-judge metrics beat guessing chunk sizes, but Ragas and LangSmith already exist.
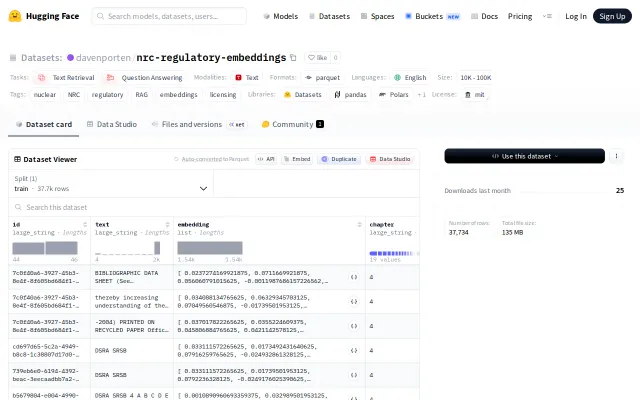
First public NRC regulatory embeddings dataset—37K chunks ready for ChromaDB and Pinecone.
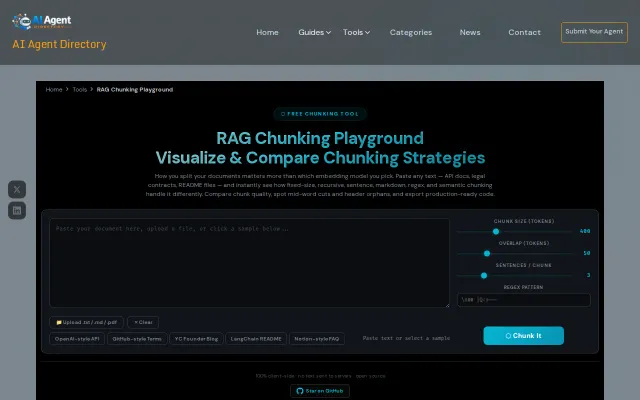
Visual chunking comparison beats guessing — export production-ready code.