AI/ML●Mid
AI-Gateway – Open-source semantic caching proxy to reduce LLM API costs
Semantic caching proxy when Helicone and Portkey already dominate.
Ship It
arnab777
103d ago
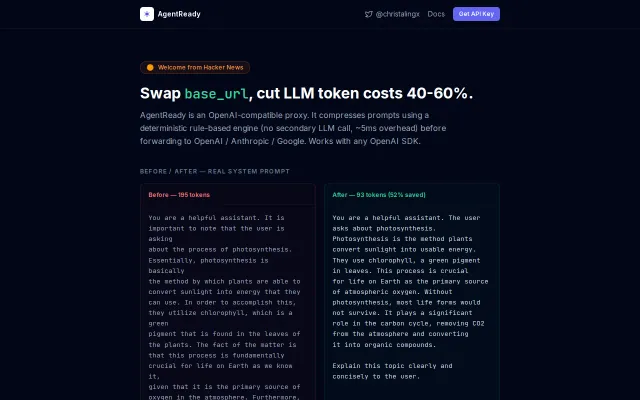
AI-Gateway reverse proxy that uses semantic caching and aims to reduce LLM API bills and token costs by 40-70%.
Semantic caching for LLMs when LiteLLM and Helicone already do this.
Developers building AI applications with high API costs
LiteLLM · Helicone · LangChain Cache
Semantic caching proxy when Helicone and Portkey already dominate.
Drop-in proxy that cuts GPT token costs 40-60% without changing app code.
OpenAI-compatible proxy with PII masking and token budgets—but LiteLLM, Helicone already do this.
Semantic caching for LLM APIs exists (Anthropic prompt caching, Langchain, Miniplex, vLLM); gateway routing is table stakes.
Local budget caps block requests before provider dashboards even update the bill.
Wire-protocol proxy means zero code changes to existing LLM clients.