AI/ML●●Solid

An opinionated ranking of 21 open-weight LLMs, filterable by your GPU
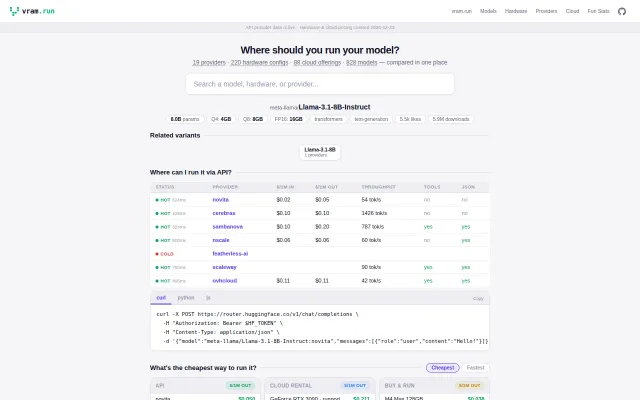
Opinionated LLM rankings with actual GPU memory math, not just benchmark scores.
Niche GemBig Brain
AndrewLiu96
211d ago
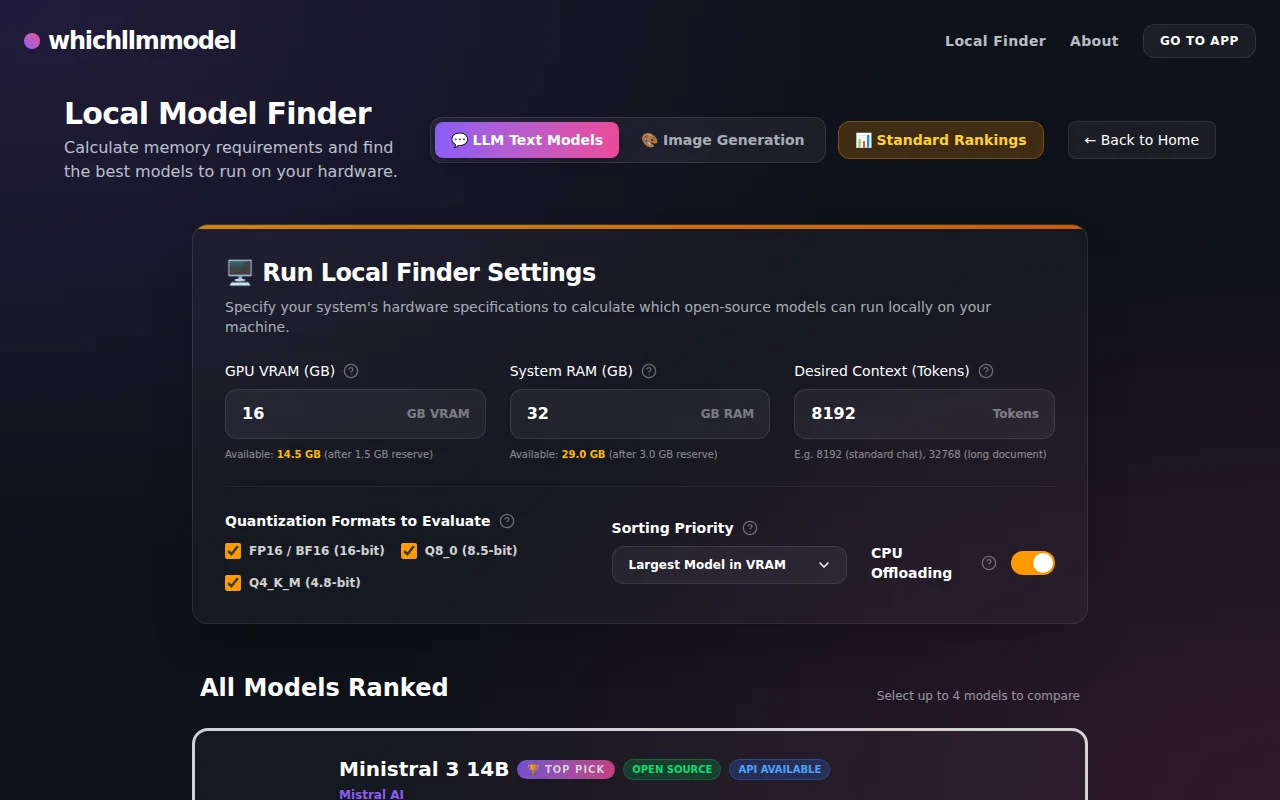
Filters LLMs by your GPU VRAM with CPU offloading calculations.
Local LLM runners, hobbyists with consumer GPUs
llama.cpp · GPT4All · Hugging Face
Opinionated LLM rankings with actual GPU memory math, not just benchmark scores.
One command finds and runs the best local LLM for your exact hardware specs.
Single lookup table: cheapest way to run any model across APIs, GPUs, or cloud.
350x faster GPU Bloom filter with academic paper backing the performance claims.
92× faster insert and 234× faster query than CPU Super Bloom on GPU.
92× faster than CPU Super Bloom with minimizer-based shard selection.