Security●●●Banger
Prompt injection detector beats ProtectAI by 19% accuracy, 8.9x smaller
Beats ProtectAI by 19% accuracy and runs 9x smaller on CPU.
Dark HorseSolve My Problem
Karan047
322mo ago
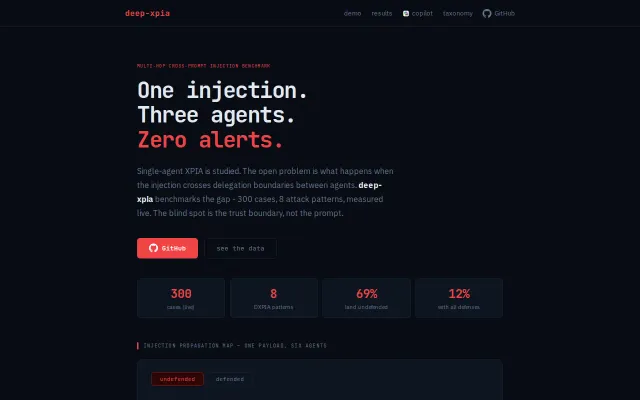
Open, model-agnostic benchmark for prompt-injection detectors — scored on both axes (attack catch-rate and false positives on real traffic), threshold-agnostic, and reproducible from raw scores.
Dual-axis measurement comparing detectors at same catch rate, not arbitrary thresholds.
AI security teams, LLM application developers, security researchers
PromptInject · Garak · LLM Security benchmarks
Beats ProtectAI by 19% accuracy and runs 9x smaller on CPU.
Outperforms existing open-source injection detectors on ProtectAI and Qualifire benchmarks.
Maps cross-agent injection attacks to real Copilot CVEs with live measurements.
Naive prompts hallucinate history; structured knowledge injection raises accuracy from 12.5% to 83.3%.
Third-party hub for Seedance 2.0 vs. Kling 3.0 side-by-side comparison when models are scattered across apps.
Tests workflow + tool + model together, not just model capability like SWE-bench.