AI/ML●●●Banger
Rapid-MLX – Run local LLMs on Mac, 2-3x faster than alternatives
Claims 4.2x Ollama speed with 0.08s cached TTFT on Apple Silicon.
WizardrySolve My Problem
raullen
942mo ago
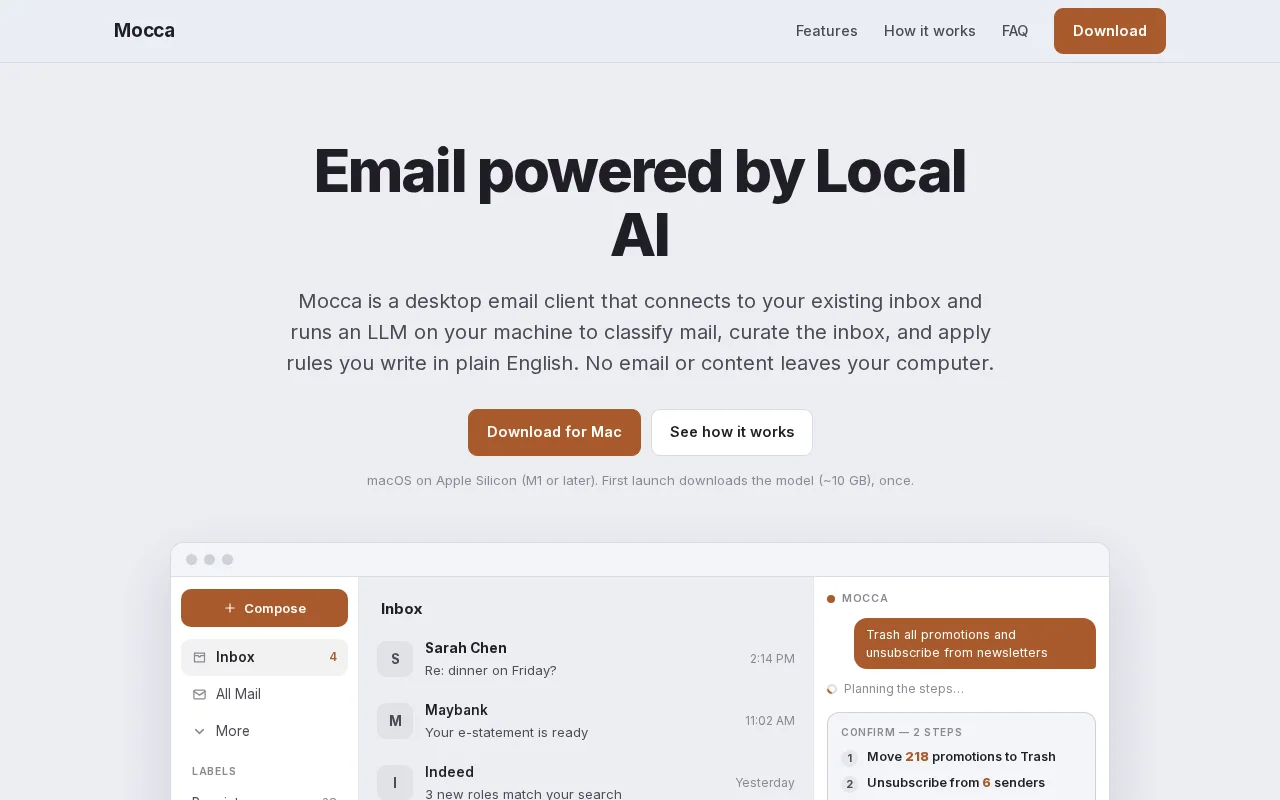
Local-only email AI on Apple Silicon when every competitor ships to the cloud.
Privacy-conscious Mac users tired of cloud-based email AI
Superhuman · Spark · Shortwave
I recently built an app called Mocca(https://mocca.run), an email client where all the AI runs locally on your Mac. No cloud and API keys. The model is bundled and runs offline.
I made it as an experiment to see whether local AI has actually gotten good enough to power a real, everyday product and not just a cool demo.
Too be honest its not quiet "there" yet but I still think it is genuinely useful for a very specific use cases.
Would love it if you guys try it out and let me know what you think
Thanks!
Claims 4.2x Ollama speed with 0.08s cached TTFT on Apple Silicon.
Fine-tune LLMs on Apple Neural Engine using reverse-engineered private frameworks — genuinely novel approach.
Wraps mlx-lm fine-tuning into a guided desktop UI, but local LLM tools are crowded.
Unlocks Apple's locked LLM with OpenAI-compatible server for existing SDKs.
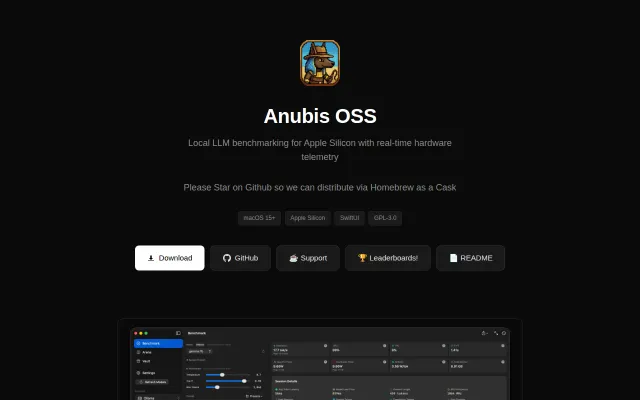
Real-time power-per-token metering across GPU/CPU/ANE—no other macOS LLM tool correlates hardware telemetry.
M3/M4 thermal-manager unlock that most older fan tools don't handle.