Education●Mid
Llama.cpp Tutorial 2026: Run GGUF Models Locally on CPU and GPU
Useful tutorial, but llama.cpp docs and Ollama already cover most of this.
Niche Gem
anju-kushwaha
1342mo ago
🚀 LLM inference Engine in Swift/Metal, Load GGUF and safe tensors modes, no conversion, no cpp, pure swift
Useful tutorial, but llama.cpp docs and Ollama already cover most of this.
Ollama and llama.cpp server already do this with more maturity and model support.
PyO3 for Swift with compile-time GIL enforcement and direct CoreML access.
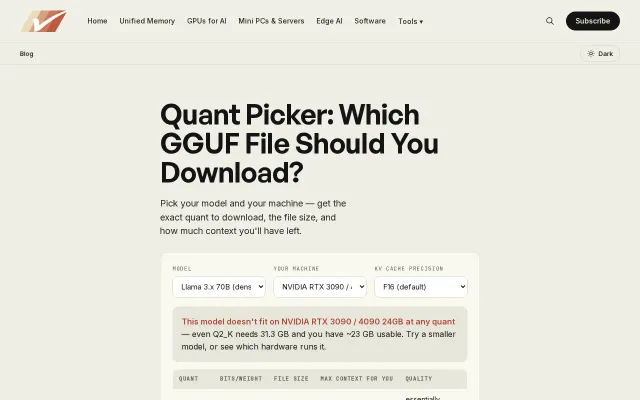
Finally answers the GGUF quant question everyone asks in Discord.
Native Swift inference with SSD streaming runs 100B MoE models without kernel panics.
Custom GGUF parser with mmap beats llama.cpp load times, but zero stars means unproven claims.