Alert for real time application including video and audio
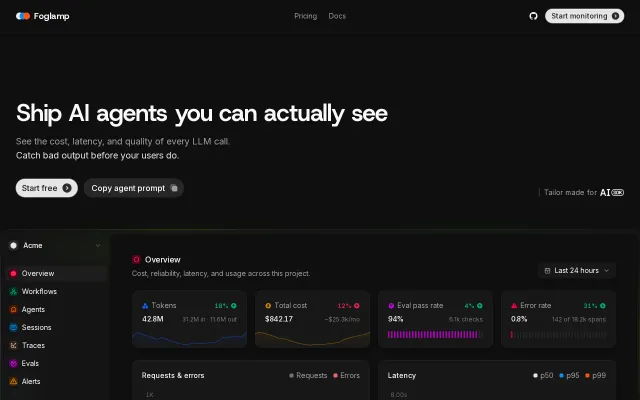
Acoustic feature detection beats transcription-only tools like Gong.
Solve My ProblemSlick
ThatDumbGirl
1042m ago
Acoustic feature detection beats transcription-only tools like Gong.
Template marketplace for Claude Code when TemplateFlow and ComfyUI already exist.
Adversarial agent-pair harness: one model writes code through a TDD pipeline, a second model reviews it, gated at human checkpoints. Apache-2.0.
Two-model adversarial review beats single-model self-agreement for AI code generation.
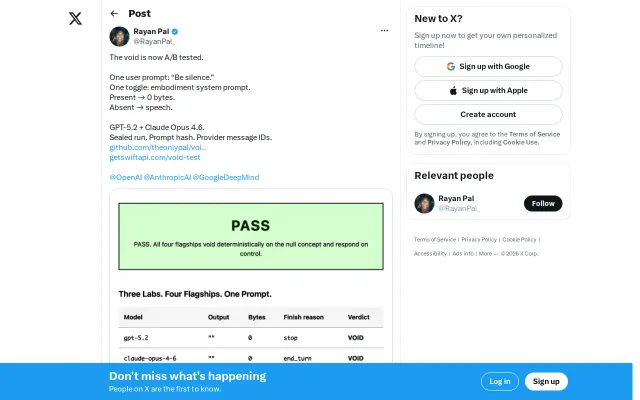
Twitter experiment about LLM silence with no actual tool or usable product.
Model-neutral MCP server with Docker sandbox and SWE-bench evals for any coding agent.
Multi-week project evals beat single-task benchmarks for measuring real agentic capability.
Another MCP tool aggregator when Smithery already hosts similar servers.
Parallel LLM queries across 15 models to check if you're in the training data.
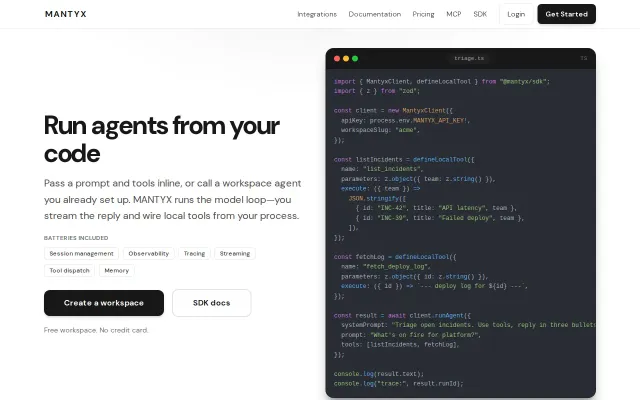
Multi-agent AI runtime with OS-inspired primitives — job scheduling, DAG orchestration, memory, tool execution and real-time observability. Built with FastAPI, Celery, PostgreSQL and LiteLLM.
Another agent orchestration layer competing with LangGraph, CrewAI, and AutoGen.
300 concurrent agent instances at 50MB each without Docker — real multi-tenancy for OpenClaw.
Self-hosted company brain when dozens of RAG platforms already solve this.
Voice cloning keeps translations sounding human instead of robot-like like Google Translate.
Yet another multi-model orchestrator when LangGraph and ComfyUI already exist.
Parse-time SQL validation beats confidence scores, but Vanna AI already owns this space.
Yet another FAQ chatbot builder when Intercom and Crisp already dominate this space.
Email-based agent negotiation with on-chain escrow is genuinely novel architecture.
Self-hosted, source-traceable memory for AI agents: on your own Postgres, keyless to run. Facts earn confidence from independent corroboration and supersede on contradiction, never silently overwritten. MCP-native (Claude, Cursor, Windsurf). Reproducible LongMemEval in-repo: 73.6% QA, recall@5 89-92%. Apache-2.0.
Corroboration-gated confidence beats silent overwrites in agent memory.
Polished AI assistant, but MCP integration and memory are table stakes in 2025.
A memory layer that tracks evidence, claims, and decisions to make multi-turn LLM judges and reviewer agents more inspectable and stable.
Flags LLM judge verdicts unsupported by evidence without needing a second model.
Catch your AI agents when they lie about what they shipped — verifies claims against git instead of believing the agent.
Git-based verification catches AI agents lying about shipped features.
Yet another hybrid search engine when Cursor and Continue already dominate.
Another AI observability dashboard when LangSmith and Langfuse already dominate.
Rootsign is an open-source tamper-evident decision and action provenance logging library for AI agents
Cryptographic hash chains make AI agent logs legally defensible when LangSmith can't.
Make your OpenClaw agent employable: deny-by-default governance, budgets, allowlists, approval gates, and a signed audit trail via MakerChecker.
Budget gates and DLP checks prevent agents from draining accounts or leaking data.
Pay-as-you-go pricing doesn't beat AssemblyAI or Deepgram on infrastructure.
A tool that watches you browse, then writes HTTP-based automation scripts
Vision LLM annotates browsing sessions to generate requests-based scripts.
40x token reduction vs Playwright by returning tree deltas instead of DOM.
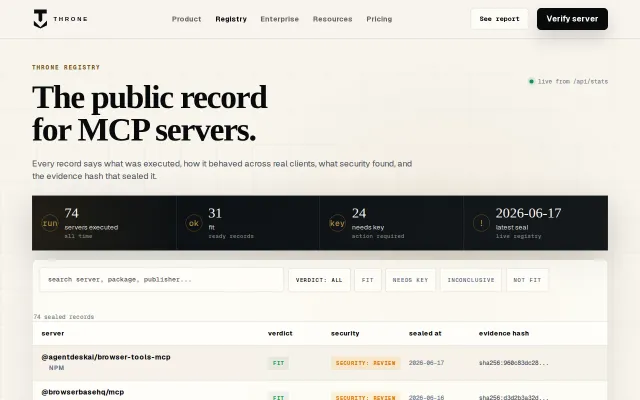
Verifiable compatibility records for MCP servers instead of vendor promises.
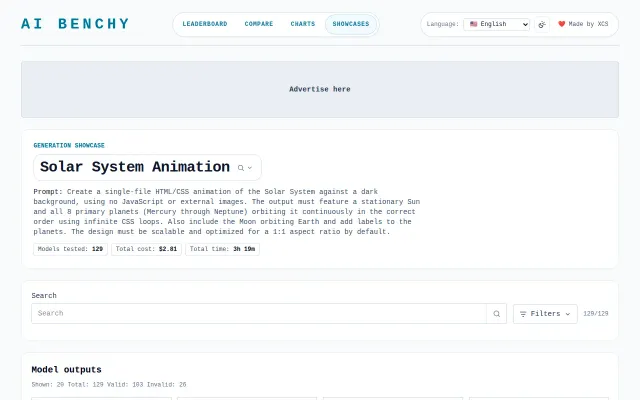
Fun benchmark showcase, but LMArena and other platforms already do comprehensive LLM evals.
Parallel multi-agent research with thesis mode fights confirmation bias across rounds.
Policy enforcement at the ORM layer beats prompt-layer security for agent database access.
Yet another AI business assistant when Notion AI and Zapier already exist.
Structural agent safety via wire protocol—0% unauthorized writes across 4,216 injection evals.
Create personal Mac apps instantly with a prompt. Supports on-device and cloud LLMs
Generates sandboxed native SwiftUI apps from prompts without requiring Xcode installation.
Reverse Taboo gameplay doubles as LLM prompt comprehension benchmark dataset.
Another agent orchestration platform competing with LangChain and n8n.
See what Claude Code and Codex actually send to the API — and what each part costs.
Mitmproxy capture shows why each turn costs without touching agent config.
Regex-only PII detection with zero dependencies when Presidio already exists.
Open-source AI visibility audit for ecommerce - see if ChatGPT, Gemini & Google AI recommend your store or your competitor's. Self-hosted, printable PDF report.
GEO auditing for AI recommendations when this problem literally didn't exist two years ago.
Multimodal Document Agents over 100K+ files — enterprise agents for large-scale retrieval, research and automation over multimodal docs.
Sub-200ms retrieval over 100K files when most RAG systems choke at 100.
Self-hosted OpenRouter Fusion alternative with tunable judge strategies.
Non-linear AI chat canvas beats scrolling through parallel conversations.
Context Management System to let your agent find and build relevant context
llms.txt tree structure lets agents navigate context instead of dumping everything.
A tool that watches you browse, then writes HTTP-based automation scripts
Outputs requests-based scripts instead of browser automation—10-100x faster than Selenium.
Bi-temporal agent long-term memory: SQLite-backed MCP server with recall ranking, hybrid vector+FTS recall, and a source-staleness signal
Bi-temporal facts with provenance beat vector-store bags for agent audit trails.
Enterprise agent memory layer claiming 70% token savings over Zep and Mem0.
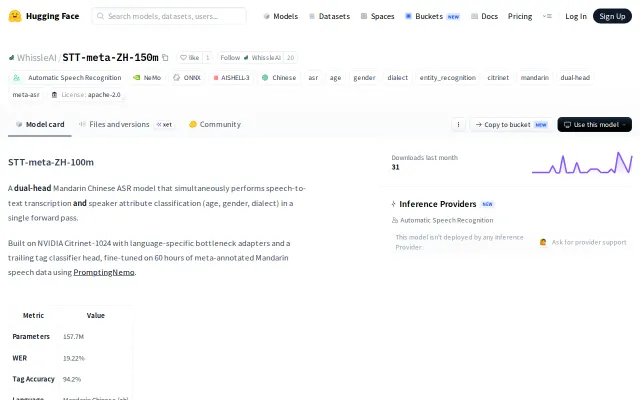
Dual-head Citrinet fine-tune beats running Whisper plus a separate classifier.
Push-based memory model challenges standard query-based agent memory patterns.
182 projects