AI/ML●●●Banger
Open-source LLM and dataset for sports forecasting (Pro Golf)
Beats GPT-5 at golf forecasting via auto-labeled data pipeline; replicable recipe for any domain via SDK.
Big BrainZero to One
bturtel
703mo ago
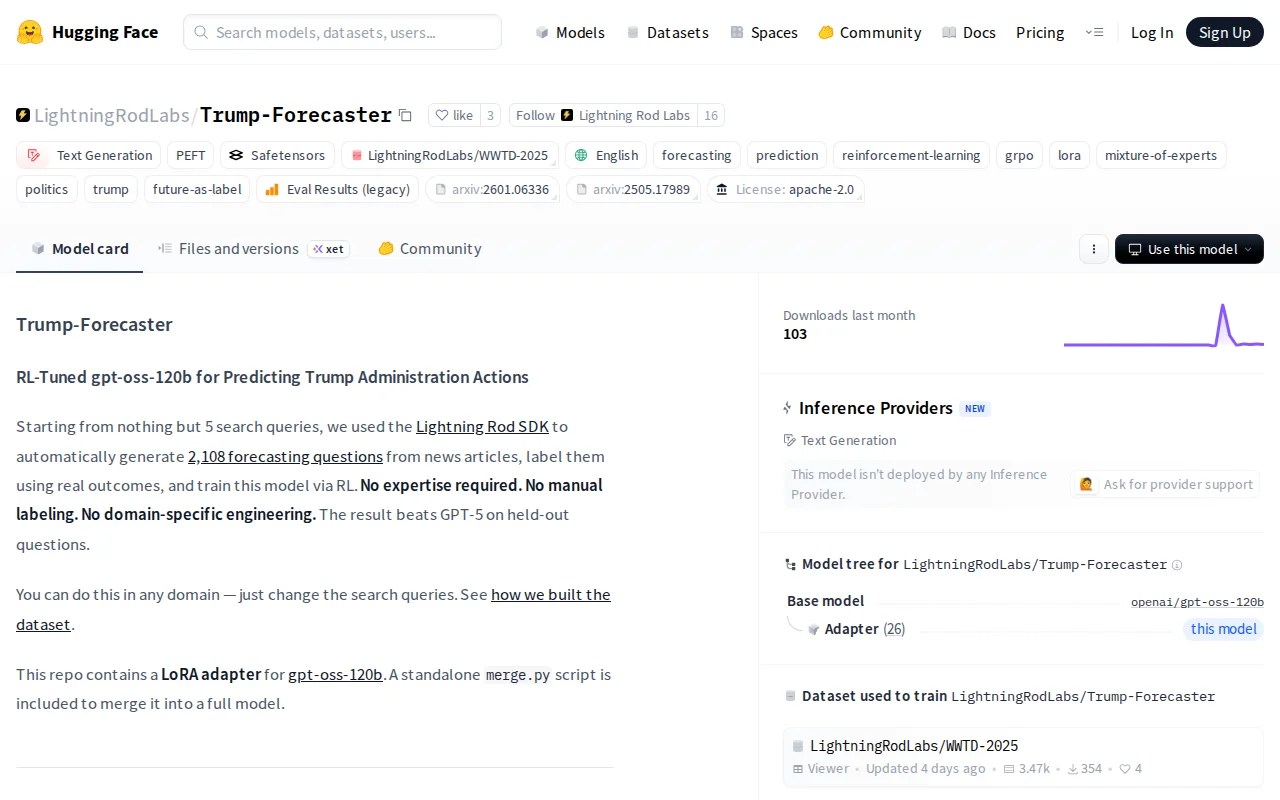
Beats GPT-5 on calibration via GRPO with auto-labeled news data.
ML researchers, forecasting enthusiasts, policy analysts
Metaculus · Kalshi · Samotsvety Forecasts
Data generation: Generated 2,108 binary forecasting questions from just a search query and a date range using the Lightning Rod SDK (https://github.com/lightning-rod-labs/lightningrod-python-sd...). Questions are generated from historic news articles — like "Will Trump impose 25% tariffs on Mexico by March 1?" — and resolved by checking what actually happened after the deadline. No human annotation — the whole pipeline is automated.
Training: GRPO with Brier score as the reward signal. LoRA rank 32, 50 training steps.
Results: Slight accuracy edge over GPT-5 (Brier 0.194 vs 0.200), but big gains in calibration — the RL-tuned model produces much better probabilities (ECE 0.079 vs 0.091).
Dataset: https://huggingface.co/datasets/LightningRodLabs/WWTD-2025
This is a fully automated way to spin up domain expert LLMs from public web data with just a few search queries, no labeling/annotation required.
I’d love any feedback, or suggestions for what domain expert to train next!
Beats GPT-5 at golf forecasting via auto-labeled data pipeline; replicable recipe for any domain via SDK.
Eval-synthesize-train loop automates custom model development better than manual fine-tuning.
LLM-based cleaning operators beat regex pipelines for messy text data.
Useful calibration dataset, but it's just logged outputs without analysis tools.
Ancient Rome Q&A benchmark shows 81pp accuracy lift, but lacks adversarial defense evidence.
Wraps mlx-lm fine-tuning into a guided desktop UI, but local LLM tools are crowded.