AI/ML●Mid
100% LLM accuracy–no fine-tuning, JSON only
Ancient Rome Q&A benchmark shows 81pp accuracy lift, but lacks adversarial defense evidence.
Big Brain
MysticBirdie
223mo ago
Fixes AI log search blindness by fine-tuning embeddings on operational data.
SREs, DevOps engineers, CTOs
Datadog AI · Splunk AI · Elastic ML
Ancient Rome Q&A benchmark shows 81pp accuracy lift, but lacks adversarial defense evidence.
Novel fine-tuning algorithm for writing, but the demo model is too small to prove the concept.
Galaxy classification model, but model card has mostly empty fields.
Eval-synthesize-train loop automates custom model development better than manual fine-tuning.
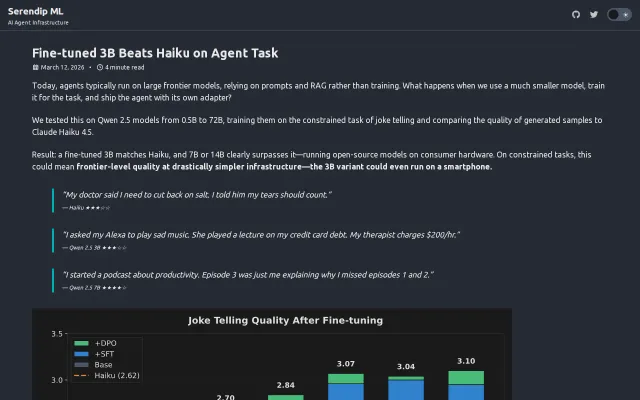
Fine-tuned 3B Qwen matches Haiku on jokes, validating small models for constrained agent tasks.
Fine-tuned Qwen 30B that prioritizes output diversity over convergent accuracy.