Developer Tools●●Solid
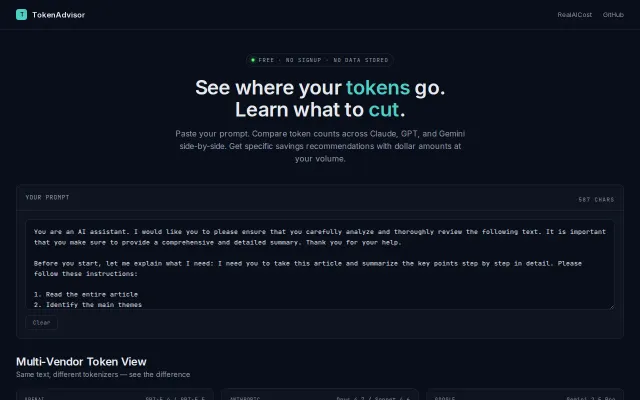
TokenAdvisor – paste a prompt, see what to cut to lower your LLM bill
Multi-vendor token comparison with specific cut recommendations and dollar savings at scale.
Solve My ProblemSlick
Emadiali83
211mo ago
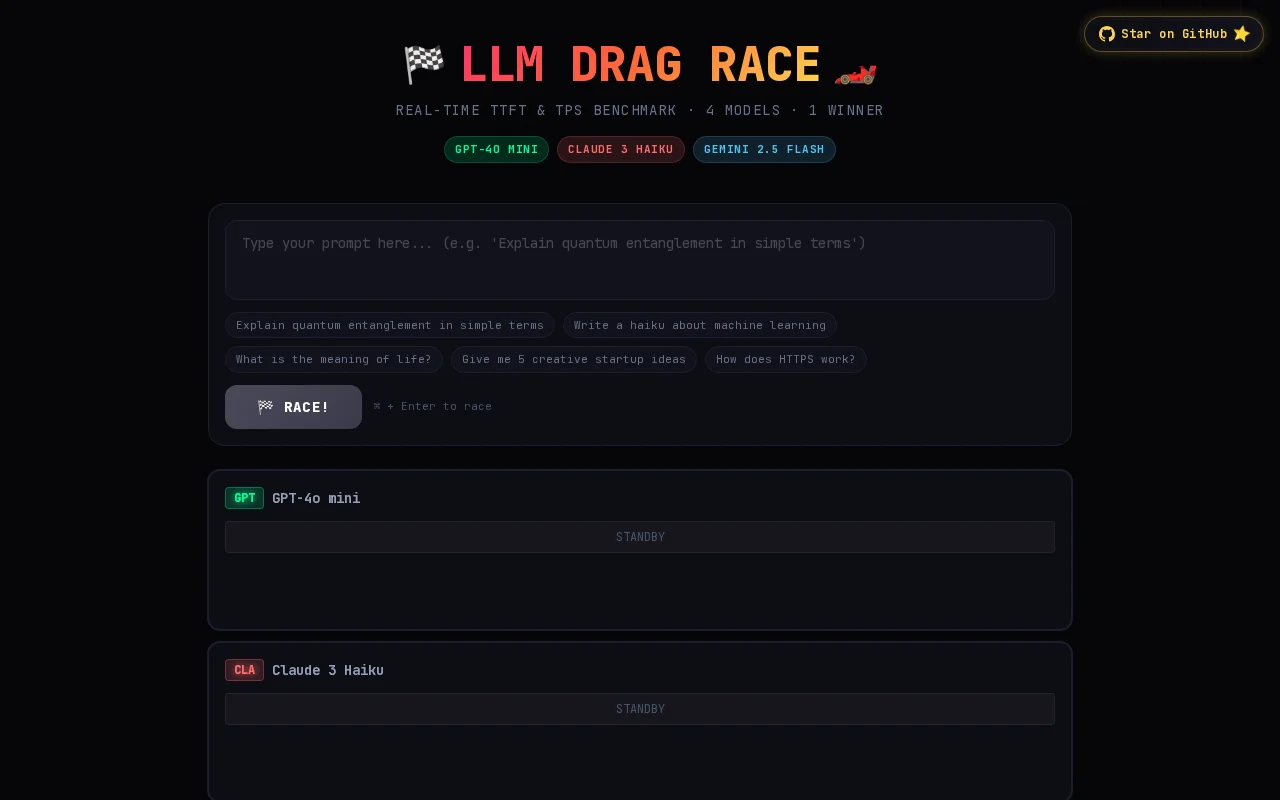
Live drag race UI, but latency benchmarks are API-dependent, not architecturally novel.
Developers choosing between LLM APIs for latency-sensitive applications
LMSys Chatbot Arena (voting-based ranking) · OpenAI's official LLM benchmarks · Anthropic's model comparison pages
Multi-vendor token comparison with specific cut recommendations and dollar savings at scale.
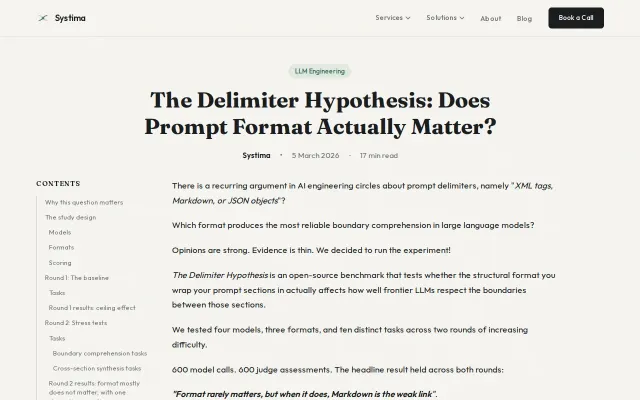
Settles the delimiter format debate with data—Markdown fails under adversarial inputs on MiniMax.
Self-benchmark shows Sentinel uses 57x fewer tokens than browser-use on hard tasks.
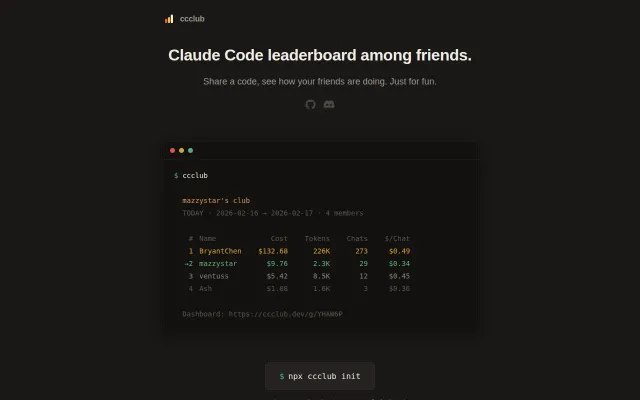
Pulls data straight from ~/.claude/projects and only uploads aggregated metrics (tokens, cost, calls) via a 6-letter invite code flow — nice and surgical. The one-command npx init + join UX and a show-data privacy audit button make adoption trivial, but it’s strictly useful only to groups already using Claude Code and requires trust that aggregated uploads are enough for your threat model.
Yet another prompt benchmarking UI when Promptfoo and LangSmith already exist.
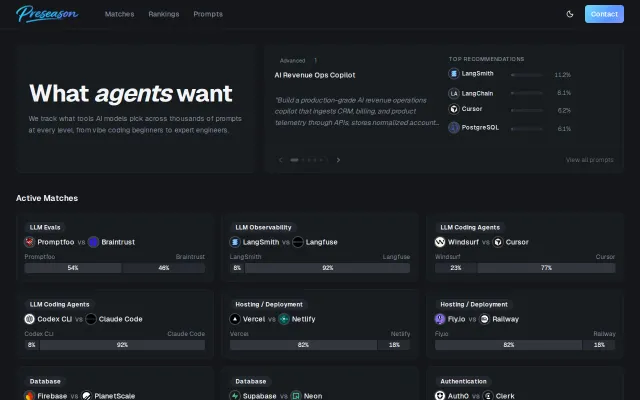
Tracks which dev tools AI agents actually choose across thousands of prompts.