AI/ML●●●Banger
Auto LLM Ranker – Describe a task in English and get ranked models
Task-specific LLM benchmarking beats generic leaderboards that ignore your actual workload.
Big BrainDark HorseZero to One
gauravvij137
303mo ago
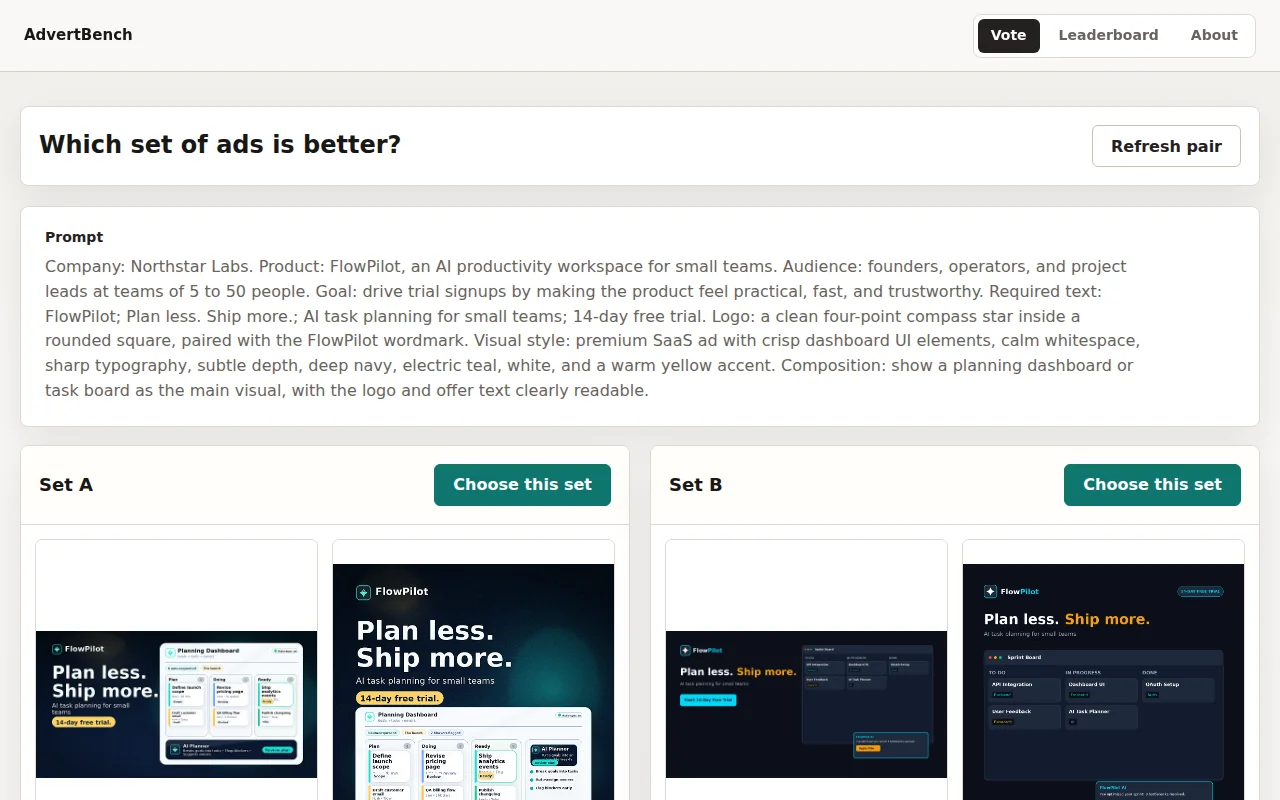
Human-voted ad benchmark as proxy for LLM tool-use ability.
AI researchers and marketers evaluating multimodal LLM capabilities
Task-specific LLM benchmarking beats generic leaderboards that ignore your actual workload.
Clever benchmark exposing LLM tokenization weakness on ASCII art, but narrow domain.
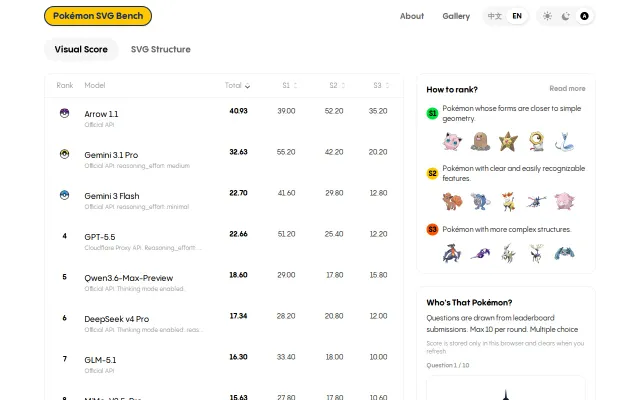
Finally, a benchmark that uses Pokémon to test if models understand complex geometry.
Ranks models by actual benchmark scores instead of just fitting the biggest model in VRAM.
Side-swapped debate matchups expose model weaknesses standard benchmarks miss.
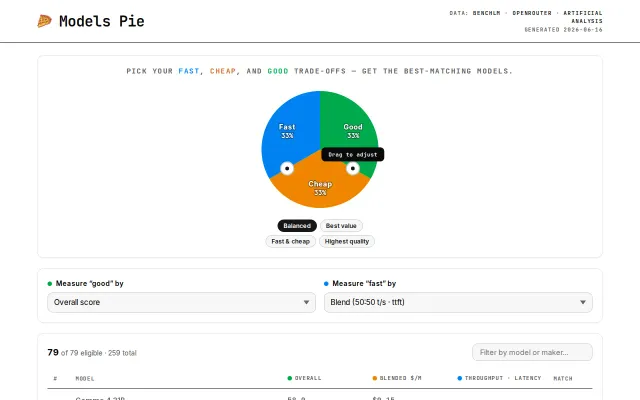
Pie chart trade-off weights beat static leaderboards for model selection.