Data●●●Banger
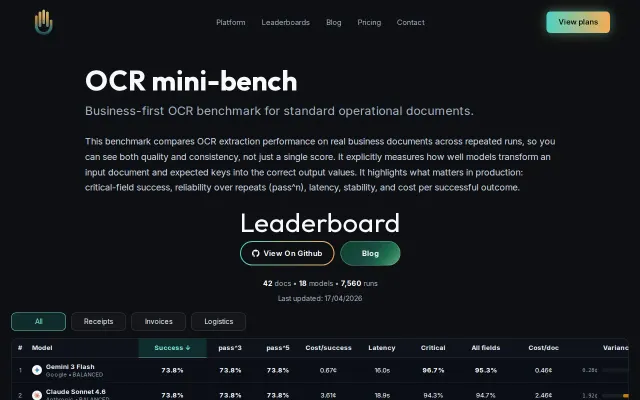
We benchmarked 18 LLMs on OCR (7K+ calls) – cheaper models win
7,560 runs proving cheaper models beat expensive ones on production OCR tasks.
Big BrainSolve My Problem
TimoKerr
511mo ago
Kitchen Rush: a benchmark for accurate AND fast native tool calling
Thinking time becomes game time lost — finally measures latency alongside accuracy.
ML engineers evaluating real-time agent models
BFCL · ToolSandbox · τ-bench
7,560 runs proving cheaper models beat expensive ones on production OCR tasks.
Opposite-narrator test catches models agreeing with both sides of same dispute.
51 models, 1613 runs, $558 spent — finally proofreading benchmarks with real numbers.
One-click LLM benchmarking with real tok/s metrics when llama.cpp requires manual setup.
Agent loop proofreading evals where HELM and LMSys are too generic.
One-command benchmark suite comparing Ollama and XGBoost performance with a shared Streamlit dashboard.