AI/ML●●●Banger
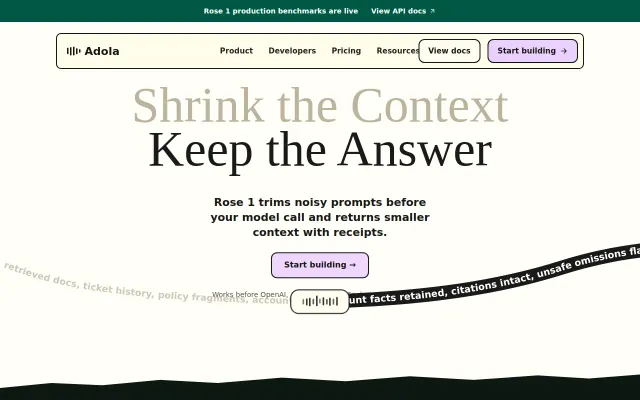
Reducing LLM input tokens by 70%
Cuts token costs 70% with receipts proving no accuracy drop on hard evals.
Zero to OneSolve My Problem
Jbunga
56331mo ago
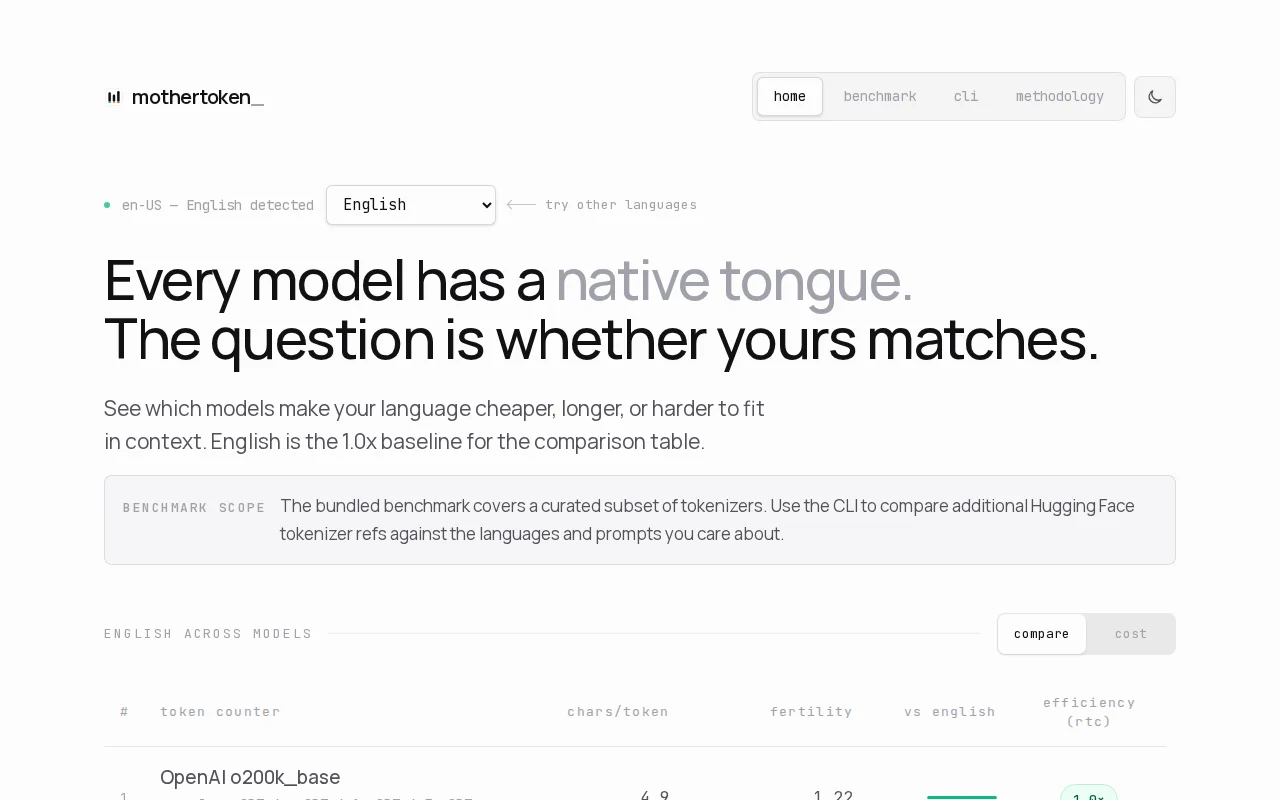
Shows which LLM tokenizers are efficient for your language, not just English.
ML engineers, non-English LLM users
Hugging Face Tokenizers · tiktoken
Cuts token costs 70% with receipts proving no accuracy drop on hard evals.
Clever benchmark exposing LLM tokenization weakness on ASCII art, but narrow domain.
Token-efficient code indexing with adaptive callers tracing cuts Claude costs by 34%.
Opposite-narrator test catches models agreeing with both sides of same dispute.
Side-swapped debate matchups expose model weaknesses standard benchmarks miss.
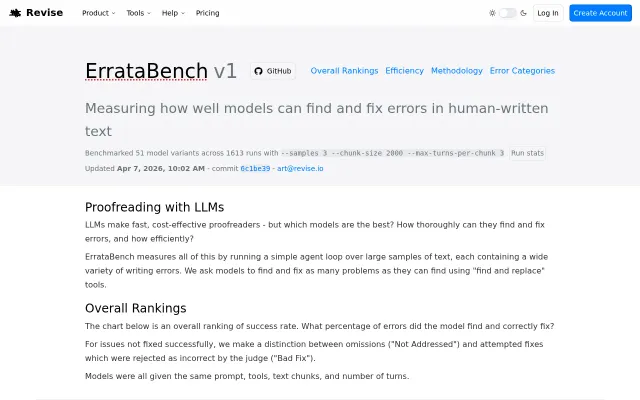
51 models, 1613 runs, $558 spent — finally proofreading benchmarks with real numbers.