AI/ML●●●Banger
Auto LLM Ranker – Describe a task in English and get ranked models
Task-specific LLM benchmarking beats generic leaderboards that ignore your actual workload.
Big BrainDark HorseZero to One
gauravvij137
303mo ago
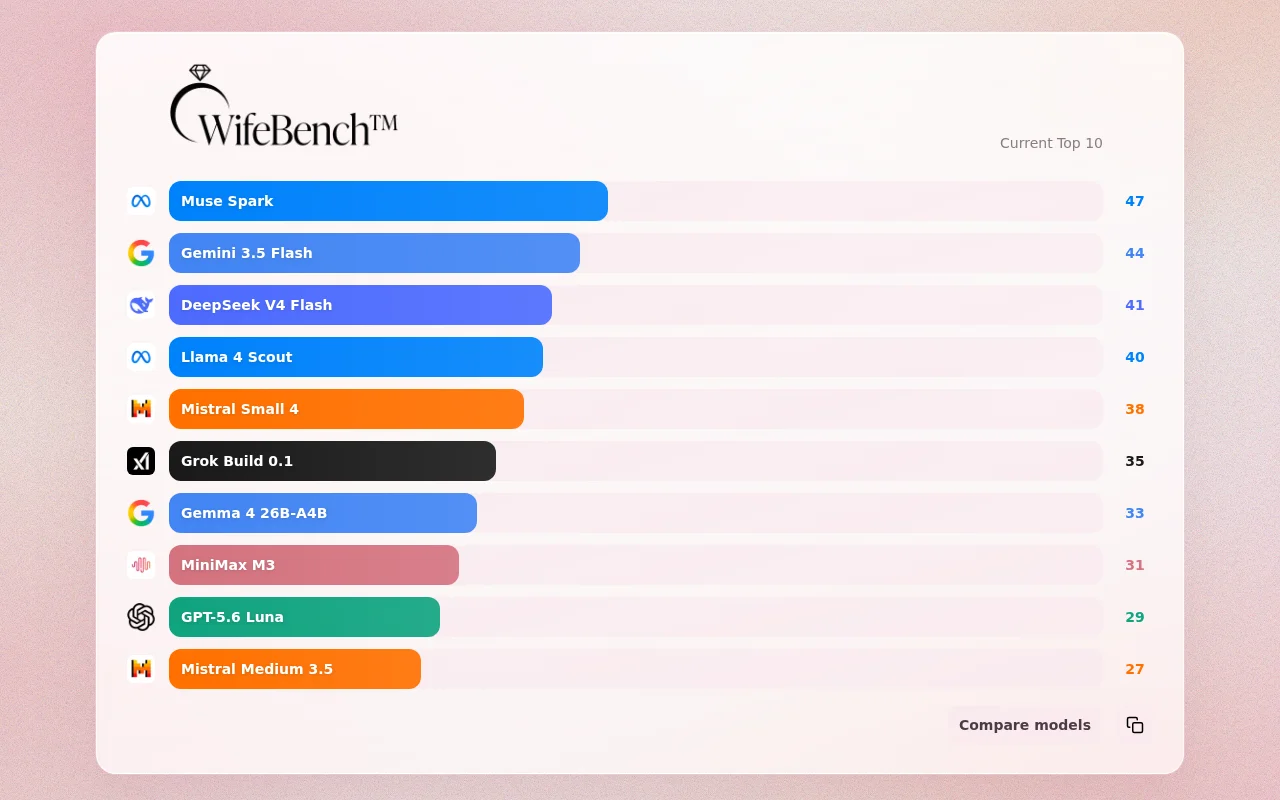
I literally had no good way of explaining it to her so I just came up with something that is approximately in the same ballpark as some of the benchmarks out there lol
Task-specific LLM benchmarking beats generic leaderboards that ignore your actual workload.
Task detection from plain English beats manual token calculators for AI coding budgets.
Human-voted ad benchmark as proxy for LLM tool-use ability.
Opinionated LLM rankings with actual GPU memory math, not just benchmark scores.
Ranks models by actual benchmark scores instead of just fitting the biggest model in VRAM.
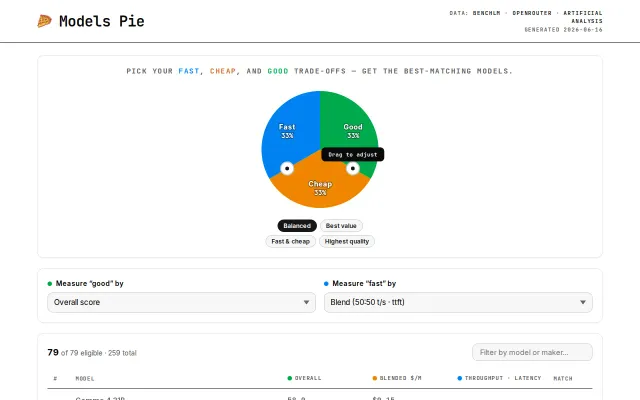
Pie chart trade-off weights beat static leaderboards for model selection.